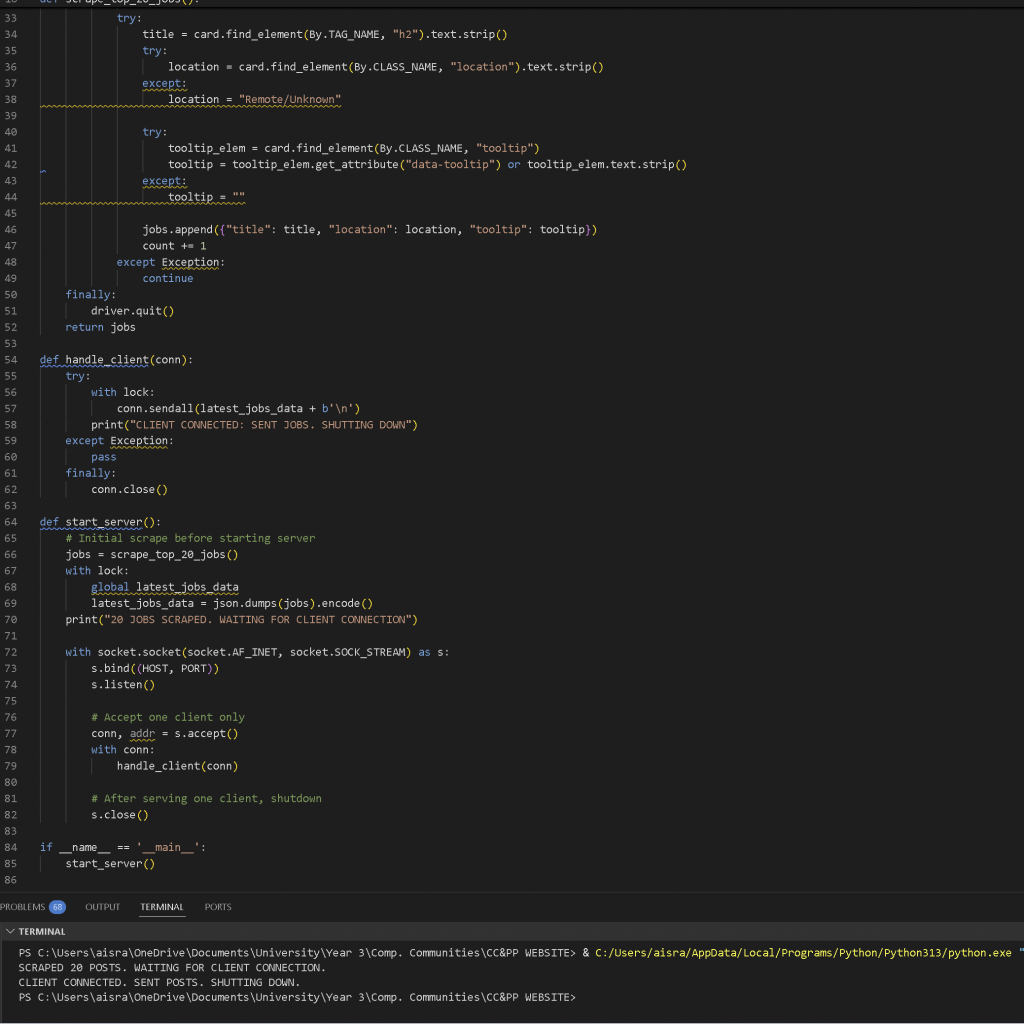
For the website media, or what the character would be looking at at work, I wanted to scrape LinkedIn. The entire process of trying to access the data, looking through API’s and trying to figure it out was very long and tiring, so I decided to look through some other options and gauge which would be the most viable.
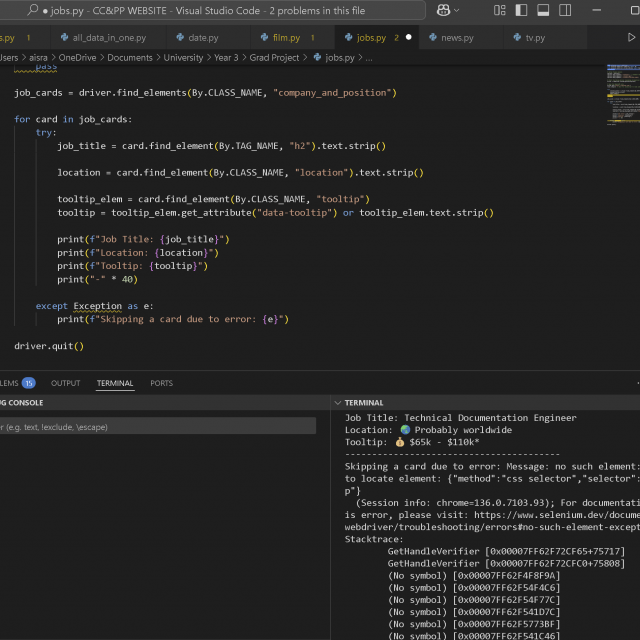
After much consideration and research, I found a website that was relatively open to scraping—RemoteOk. This site updated quite frequently when I checked it over the days so I was confident it would be able to convey the message I wanted. I was able to access the data I needed almost immediately. Initially, I encountered a few errors, but they were fairly basic and stemmed from incorrectly handling the HTML elements during inspection.
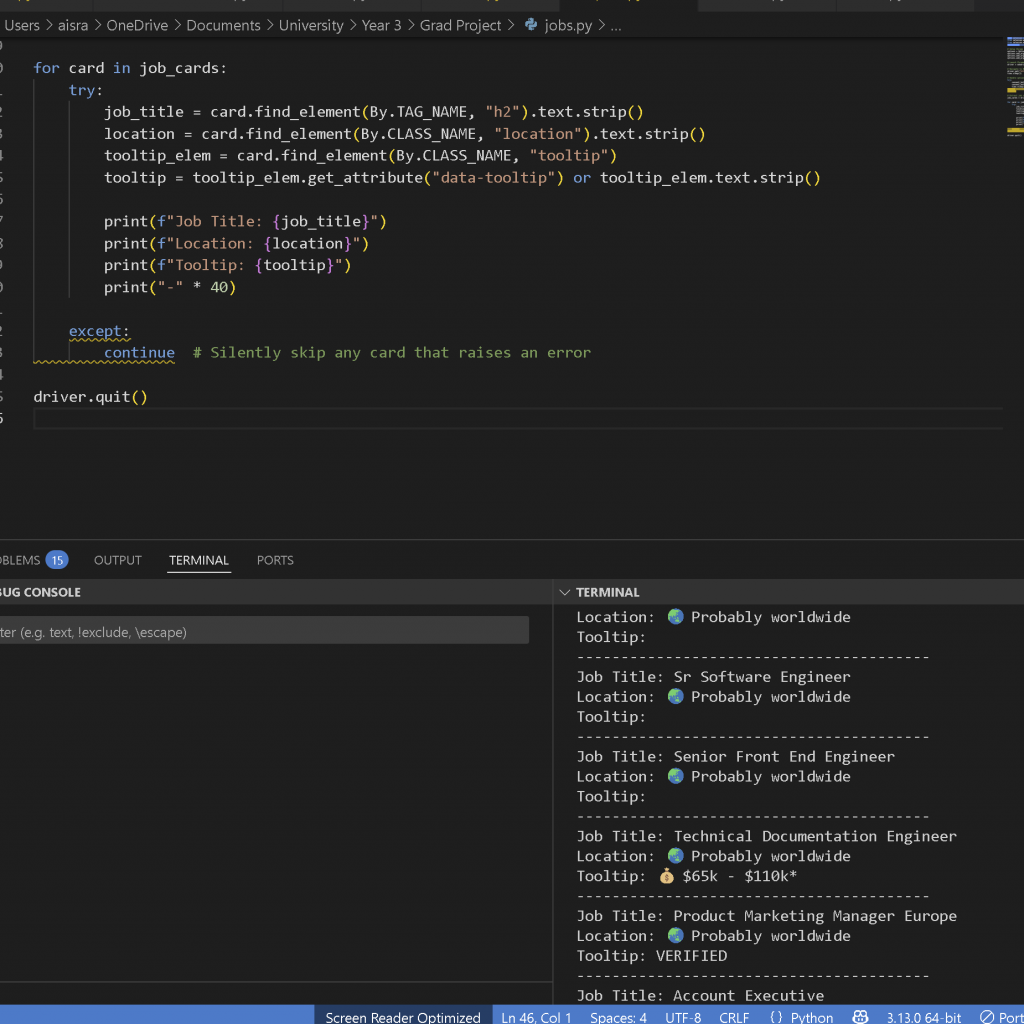
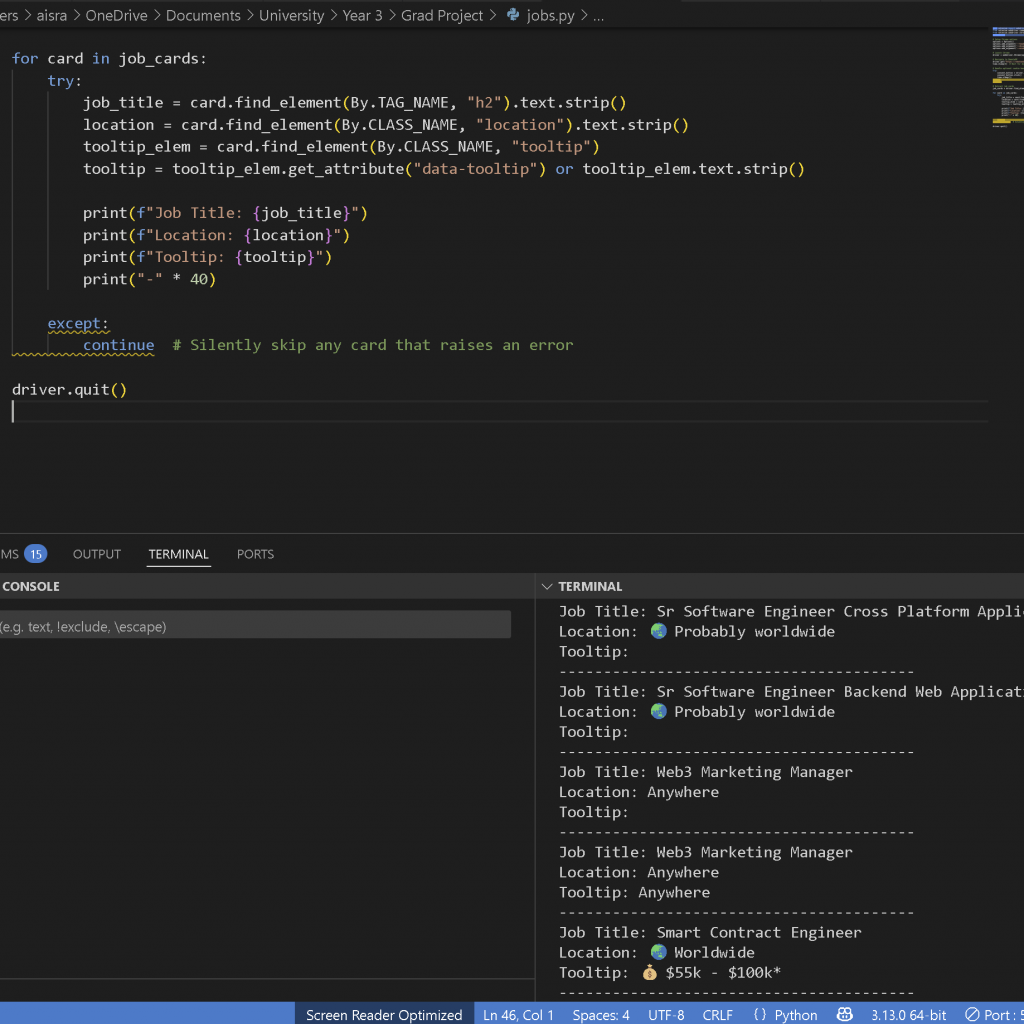
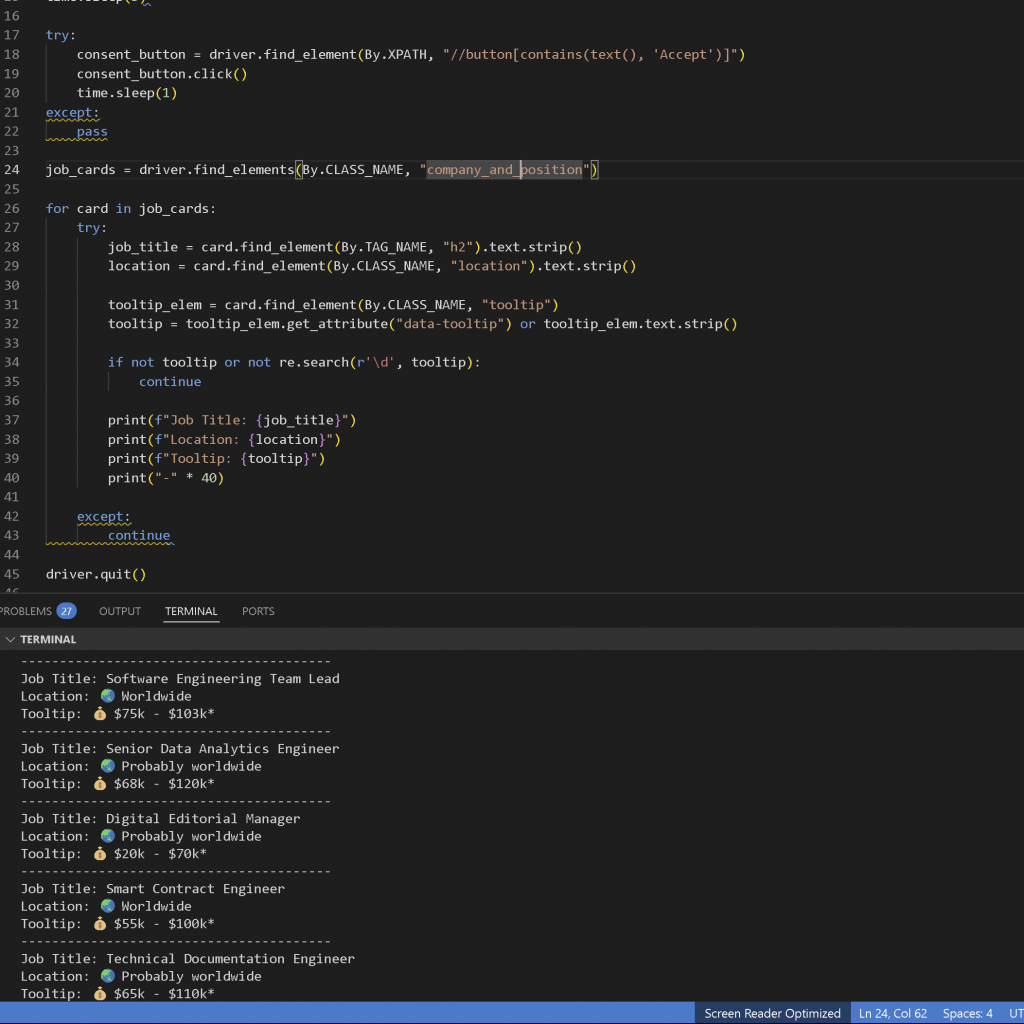
After resolving the initial issues, I was able to extract the data I needed. Some of the tooltips or salary fields were either blank or didn’t contain any monetary value, but I managed to filter these out and focus only on fully filled job listings, which were relatively easy to access. I then turned this into a socket server setup, ensuring that it scraped the data, sent it to the client, then went to sleep for a while before refreshing the site and scraping again.
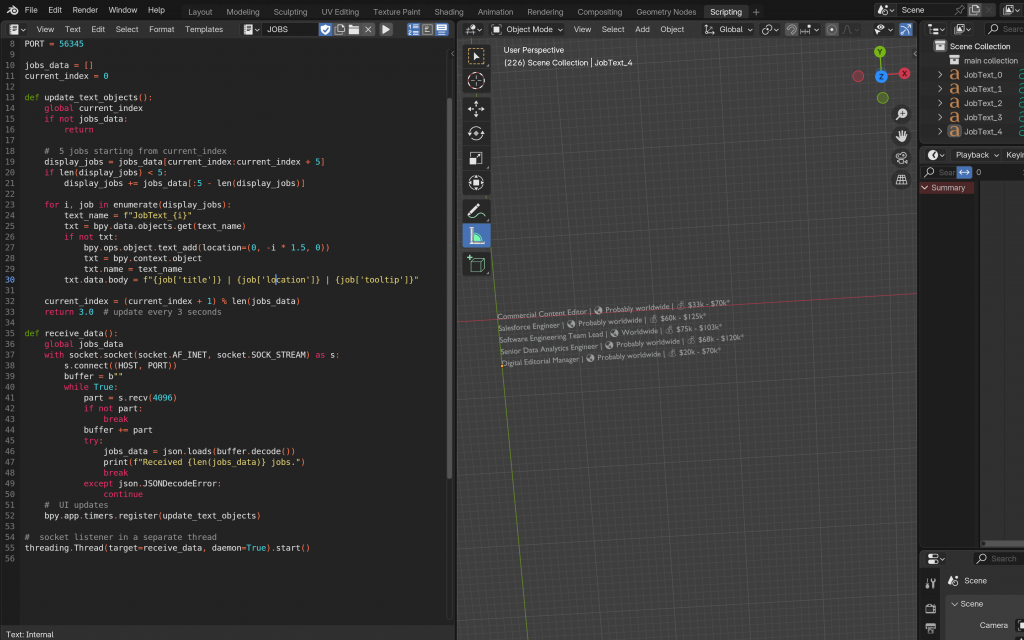
I then moved on to visualising the data. This process was relatively quick, as I reused logic from previous implementations, making it a fairly short and smooth task. I began by scraping the first five job listings and displaying them on the screen. I wasn’t sure how much data to scrape initially, as the scene length was still uncertain. Eventually, I decided to start with a fixed number—20 job listings—and display them in four batches of five. I planned to adjust the pacing later by varying how long each batch stayed on screen and scrolled, depending on the final duration of the scene. I then also combined all job objects into one for easier animation.
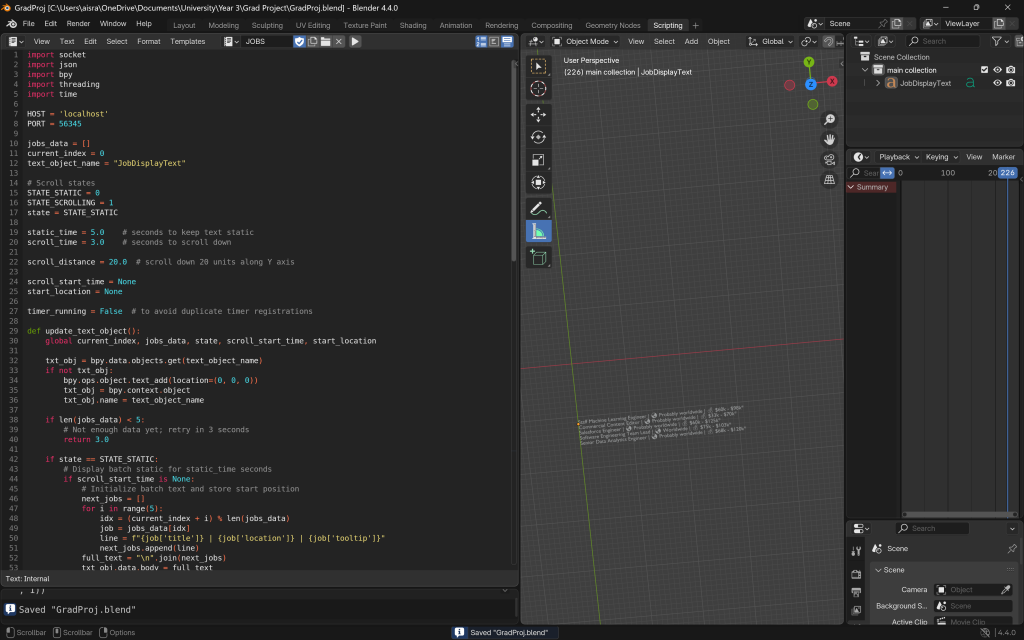
Once I combined the text into a single object, I began implementing the logic to display the data in sequential batches. Each batch would appear, remain static for a few seconds, then scroll down. After that, the next batch would appear at the original position and follow the same sequence, continuing until all 20 job listings were shown. Once complete, the object would be deleted to make way for the next set of visuals.
This stage was quite challenging. I ran into several logical errors and glitches—some of which I asked ChatGPT about but couldn’t resolve at the time. I had to troubleshoot issues like batches starting where the previous one had just finished scrolling, which led to overlaps and unexpected behavior. It took a lot of trial and error to figure out what was causing these problems and to fix them.
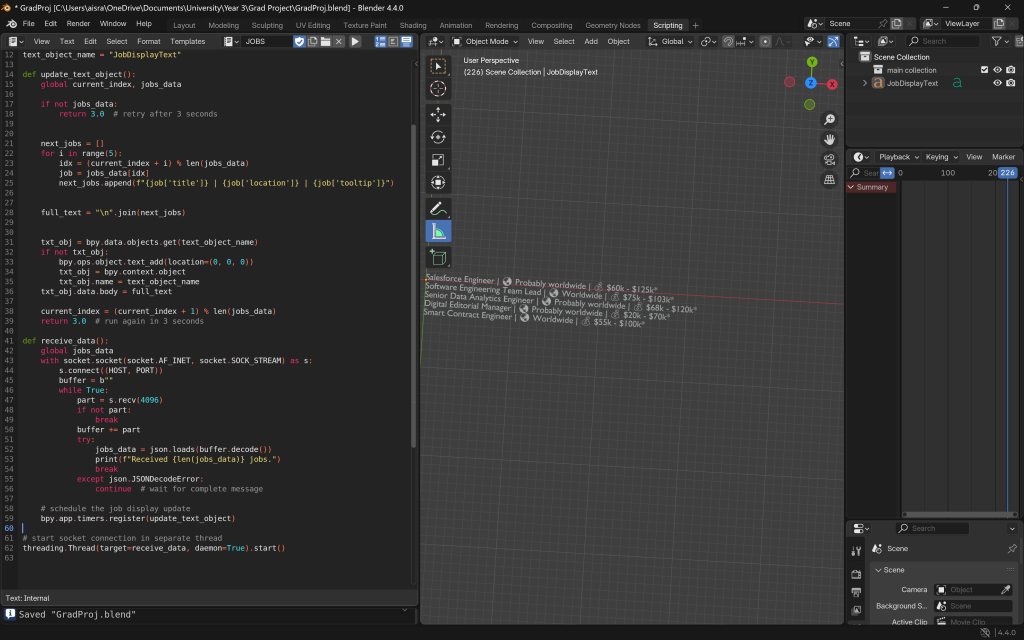
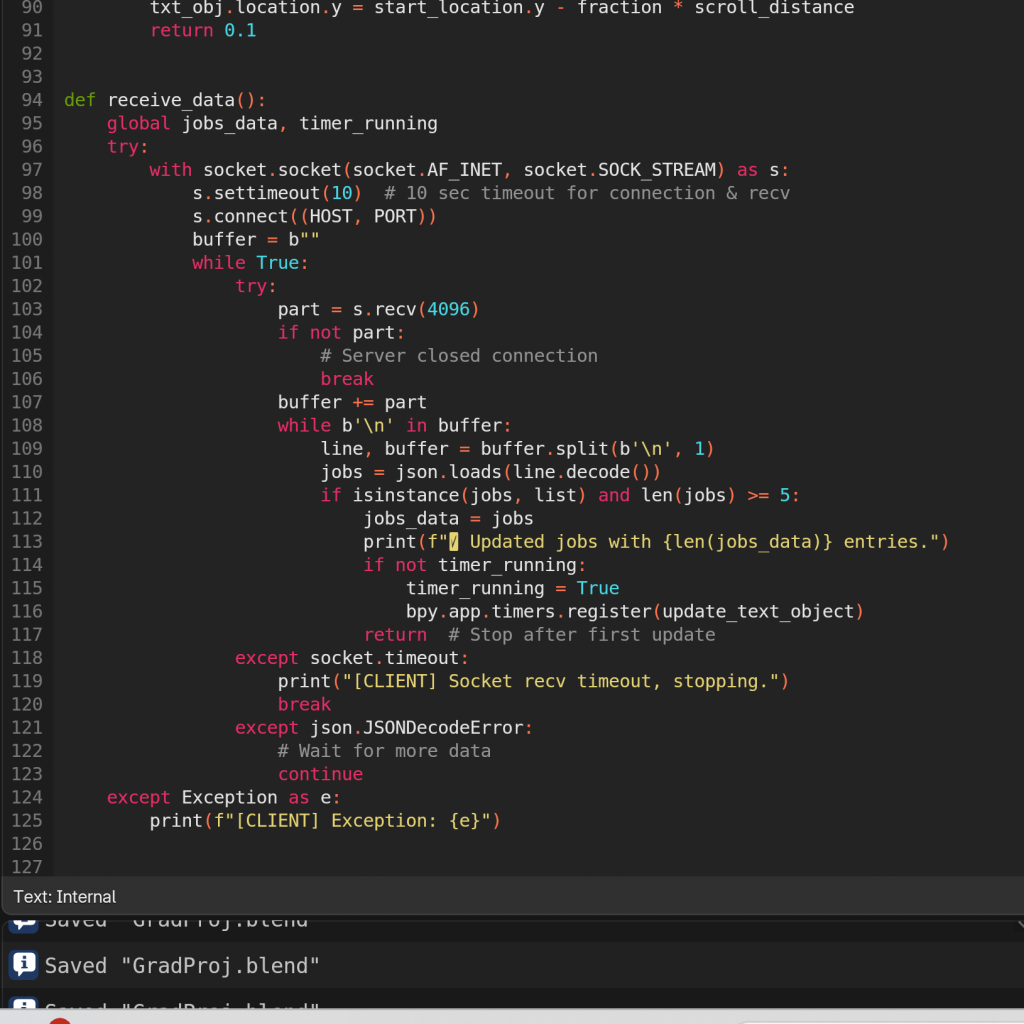
Once this was done, and after a gap in time during which I explored scraping news data, I returned to this project with a fresh perspective. I realised that the overall process needed simplification. So, I made several adjustments to streamline everything—from how data was scraped to how it was visualised—removing unnecessary complexity wherever possible.
I removed the looping logic and stopped Blender from always listening on the socket. Instead, the server now scrapes the necessary data just once, sends it to Blender upon connection, and then shuts down—no more sleeping and re-sending. On Blender’s side, it receives the data once, updates accordingly, and proceeds with the animation without waiting for further updates.