For the cinema data, I had several options to choose from—such as scraping websites like Odeon or Vue, or pulling search results from Google for what’s currently showing in London. There were various ways to approach this, but I initially focused on the Prince Charles Cinema website. By inspecting the site’s network traffic, I realized it wasn’t dynamically loaded and didn’t have strong anti-scraping measures in place. This made it a good candidate for scraping.
I used BeautifulSoup and Requests to scrape the movies showing that day, then visualized the data in Blender. There was some trial and error involved in identifying where to scrape the relevant titles from, specifically from the <a class="liveeventtitle"> tag, but after a few tests, I managed to get it working as expected.
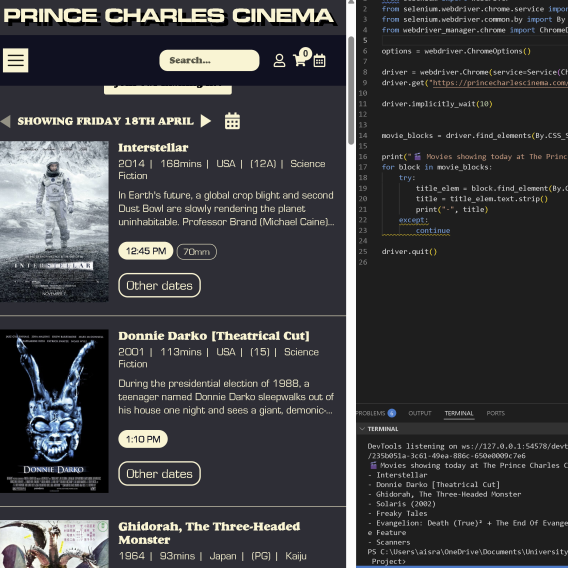
Next, I used Selenium to scrape the data dynamically, ensuring the code could handle daily changes on the homepage. After that, I wrote some basic scripting to visualize the data in Blender. I set up a socket client-server connection between VSCode and Blender, which worked successfully. This setup allowed the text to update automatically each day, reflecting the changes on the homepage when the script was run.
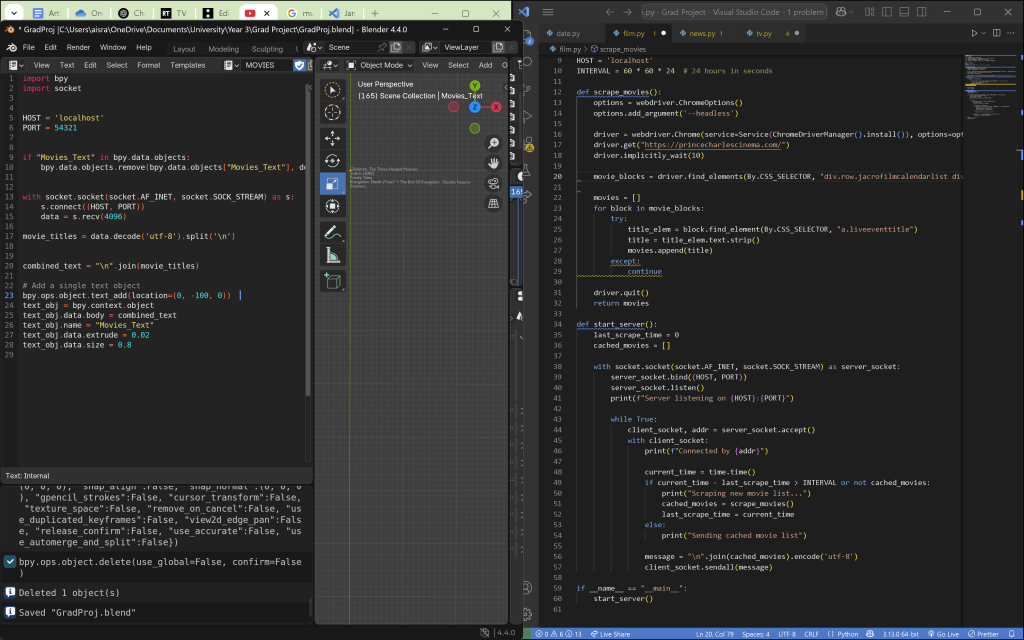
After some reflection, I realized there were several issues with my initial approach. One problem was that the Prince Charles Cinema doesn’t screen many films in a single day, which limited the potential for a more exciting and visually engaging animation. Additionally, I wanted my project to reflect the fast-paced nature of media consumption—the fact that much of the content we engage with is recent and ever-changing. However, this cinema tends to cater to cinephiles who enjoy re-watching critically acclaimed films, often showing movies that can be decades old. As a result, the titles scraped from this cinema wouldn’t provide the “evergreen” animation I aimed for, which needed to constantly reference current content to remain relevant. Given these factors, I decided it would be better to pursue a different approach.
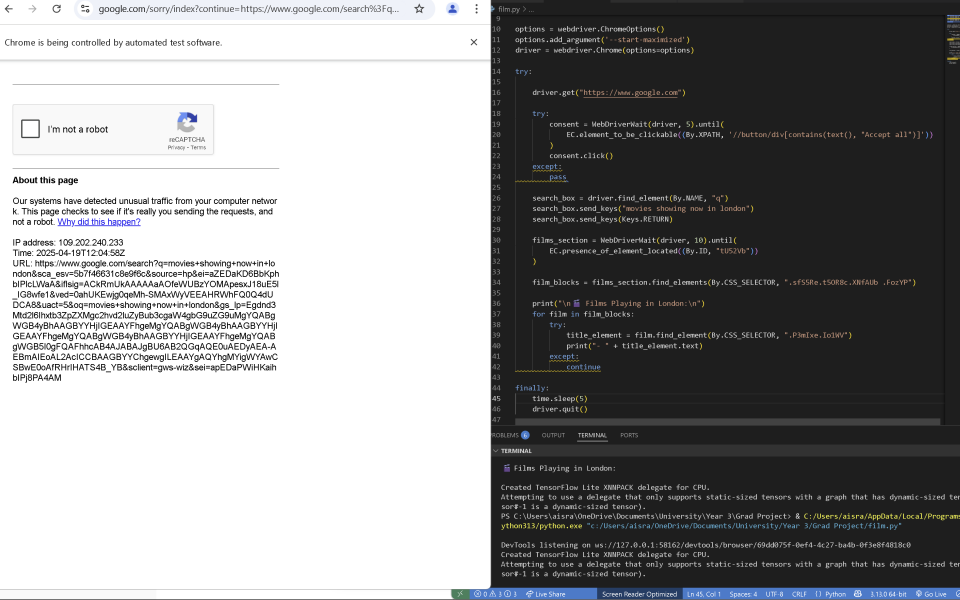
The next step I tried was scraping film listings from Google by searching for “movies showing now in London.” This approach seemed promising, as it would aggregate films from multiple cinemas into one neat package, eliminating the need to select a specific cinema. However, I overlooked the fact that Google has robust anti-scraping measures in place. I spent a considerable amount of time experimenting with different methods to bypass these restrictions, but ultimately, I was unsuccessful. I followed several YouTube tutorials, but each one eventually recommended using a paid API to make this possible.
I tried various methods to bypass the CAPTCHA and scrape the data legally and safely. This included using undetected-chromedriver (a stealthy browser automation tool), setting a realistic user-agent, adjusting the screen size, adding delays, and interacting with the page slowly to mimic human behavior—all while avoiding too many requests from a single IP. Despite these efforts, the only progress I made was by solving the CAPTCHA manually and integrating that functionality into the code, which wasn’t ideal for my end goal. After several unsuccessful attempts, I decided to move on to the next approach for scraping this information.
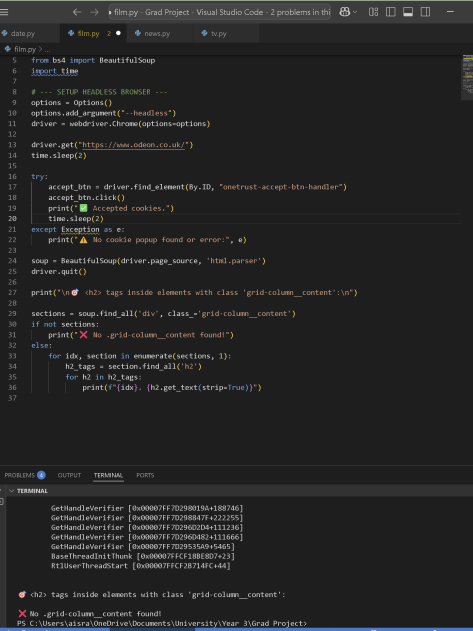
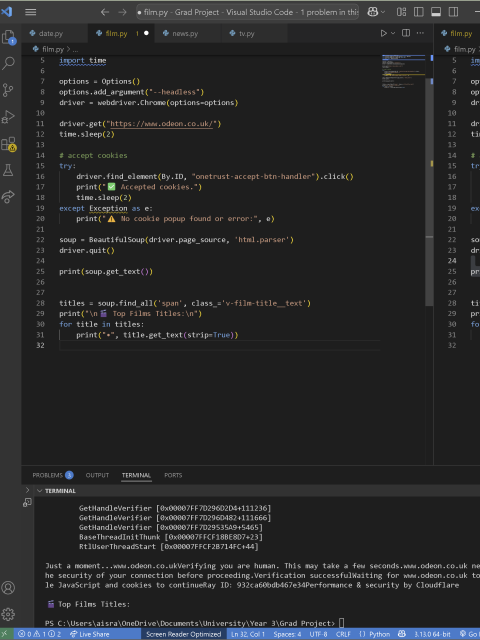
I then turned to scraping movie aggregator websites of major cinema chains, of which there were several to choose from. I started with Odeon, as seen above. Odeon’s website is JavaScript-heavy, with many attributes loaded lazily, so I had to carefully debug and research solutions, like using the scrollTo function to load the content.
After some trouble accessing the data, I asked ChatGPT for help, which pointed out several potential issues, such as cookies pop-ups blocking access to the data. I added code to click ‘Accept Cookies’ using the button ID, then parsed the updated content with BeautifulSoup before extracting the page source. However, this still didn’t work. After further debugging, I received an error message containing the phrase “ID: 932ca60bdb467e34Performance & security by Cloudflare,” which indicated that the website was using Cloudflare security to verify human traffic, likely blocking the bot (Selenium) from accessing the page properly.
I decided to explore other options. First, I tried Playwright but ran into installation issues. Next, I found an API for scraping the Odeon website, which seemed like a potential solution.
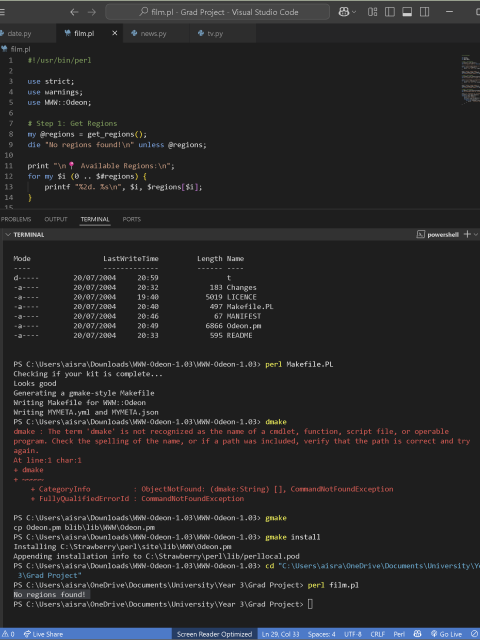
The module required the use of Perl, so I downloaded it and went through the installation process. I began by installing WWW::Odeon from the WWW-Odeon-1.03.tar.gz package using the following steps: perl Makefile.PL, make, make test, and make install. This module was designed to list all regions, allow you to select one, list cinemas in that region, pick a cinema, and then print the movie listings and showtimes for that cinema.
I thought I could leverage this module to scrape movie listings for all cinemas in London. However, the installation process was quite different from anything I had done before—quite challenging, but also a good learning experience. Below is a snippet of that process.
I reviewed the documentation for WWW::Odeon and familiarized myself with basic Perl using resources from learn.perl.org and a YouTube playlist (link). Although I initially turned to ChatGPT for help, it didn’t quite provide the guidance I was hoping for. So, I went through the playlist, practiced with some exercises, and ended up learning a lot about Perl. However, I made a crucial oversight—I didn’t check how outdated the WWW::Odeon module was. Created in 2004, it’s no longer compatible with Odeon’s modern, dynamic website. In hindsight, I should have verified the module’s viability before dedicating so much time to understanding Perl and completing all the installations.
I attempted to inspect the structure of the WWW::Odeon module and patch the existing scraping logic to work with Odeon’s updated website and API. I also experimented with switching out scraper libraries. However, I quickly hit a major roadblock—the Network tab in the browser’s developer tools didn’t show any useful requests. This suggested that the site might be using technologies like WebSockets, WebRTC, or Server-Sent Events (SSE) to render content. At that point, it became clear that scraping Odeon would require overcoming too many obstacles, which was beyond the scope of my project. Despite having already invested a significant amount of time, I decided to cut my losses and explore a different approach instead of continuing down a potentially endless rabbit hole.
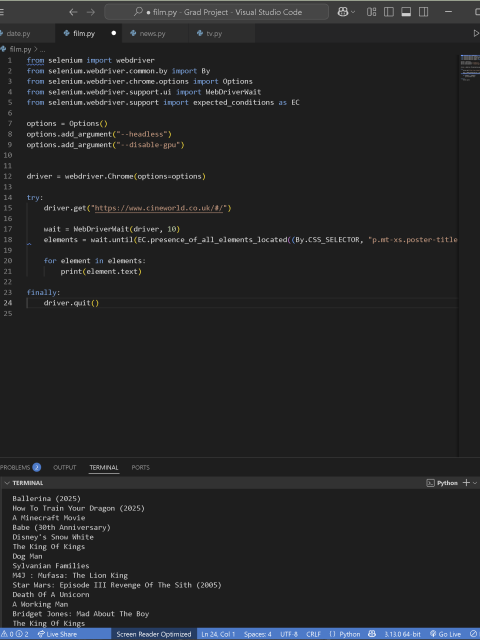
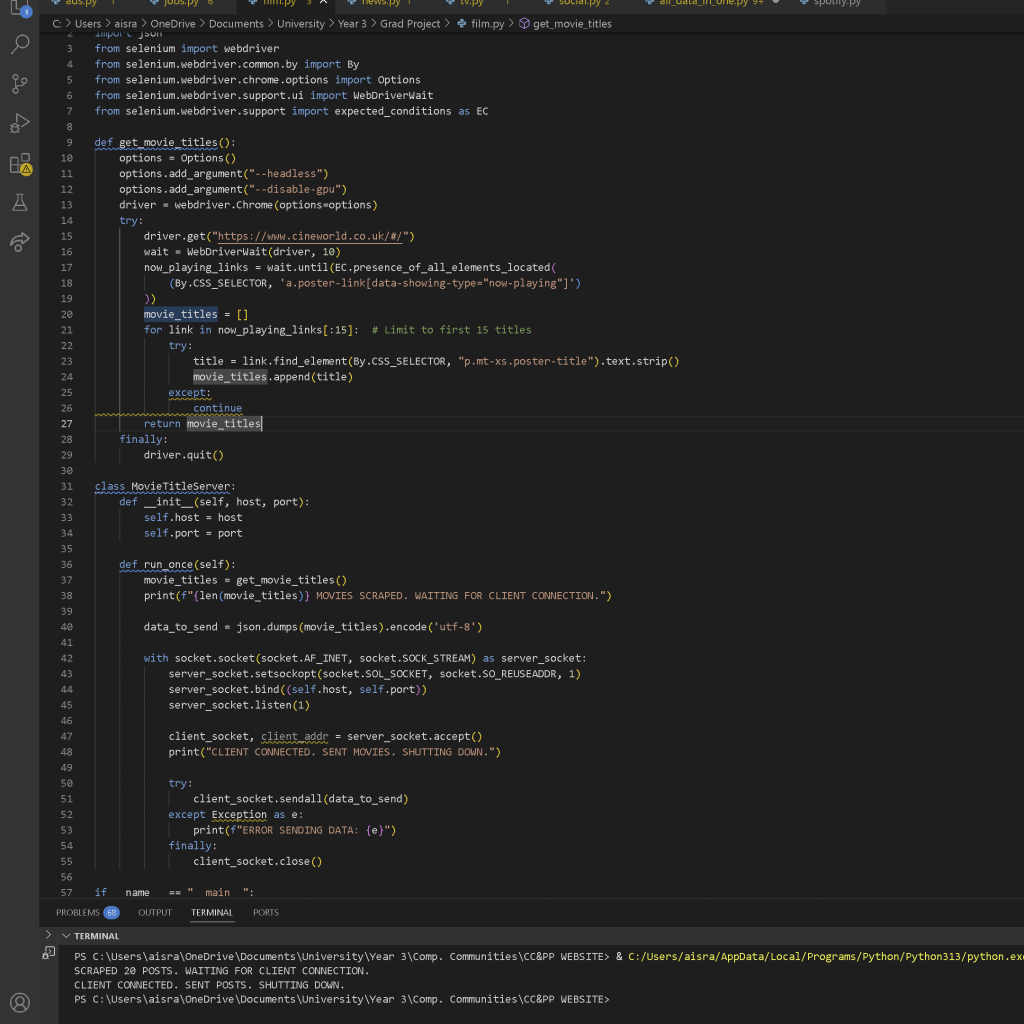
I then shifted to scraping the Cineworld site, which proved to be much easier. It displayed recent movies and didn’t present any major roadblocks, allowing me to work at a level that was both comfortable and challenging. Initially, many elements were grouped under the same class without unique identifiers, causing me to scrape more data than I needed. However, after some searching, I was able to narrow it down by finding the data-showing-type identifier and ensuring it was set to “now-playing,” allowing me to scrape only the relevant data.
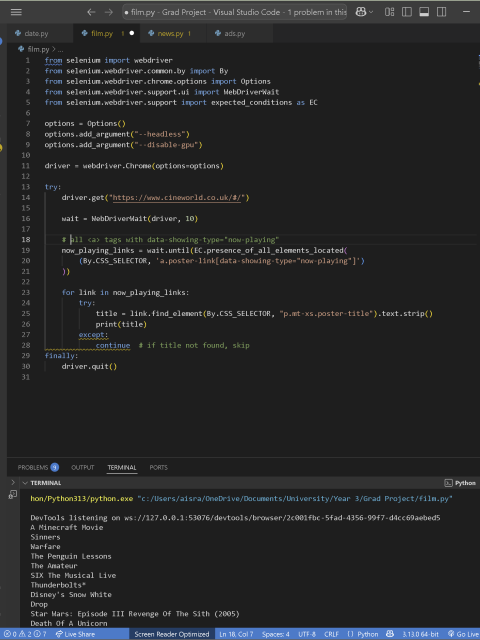

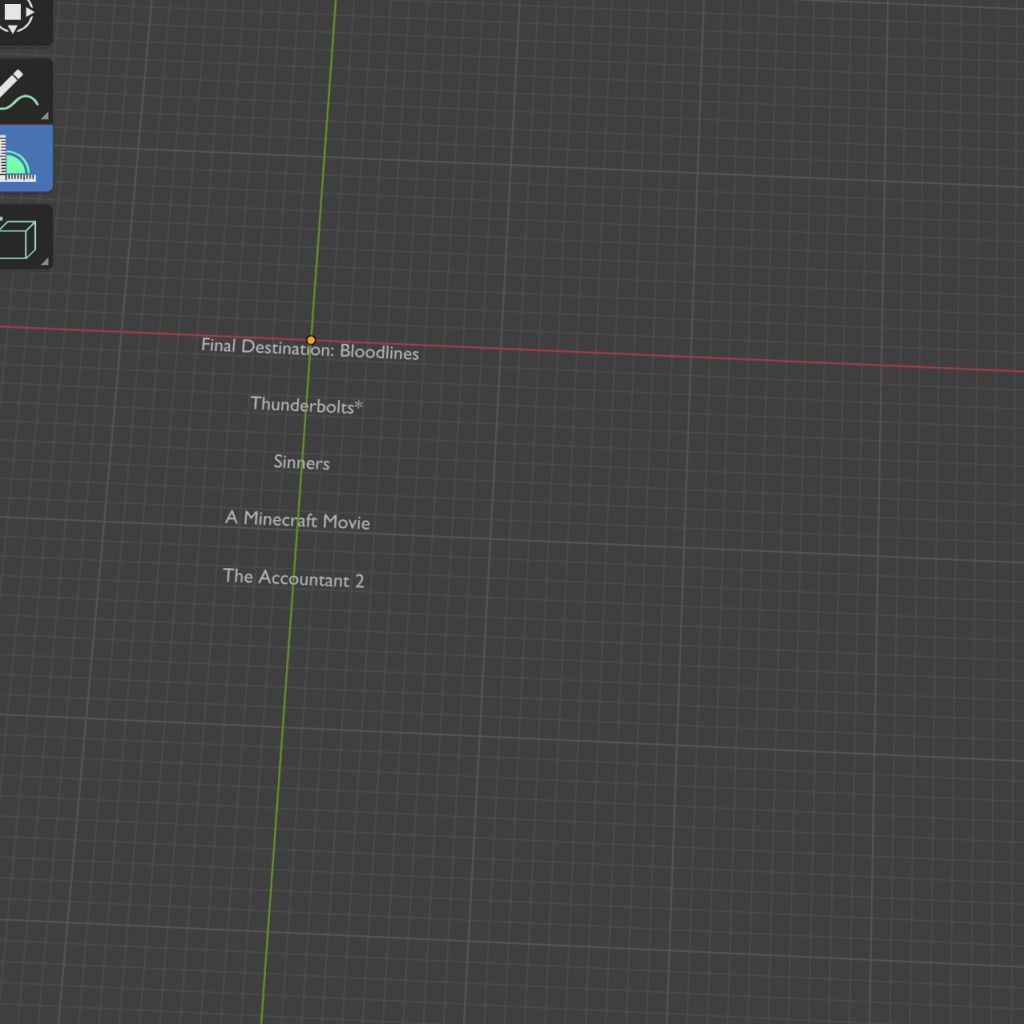
Once the scraping was complete, I was able to visualize the data in Blender at a basic level. I then implemented some logic so that five movie titles would appear at a time for 10 seconds, after which the next five would be displayed, and so on. To enhance the effect, each title would flash white (from black) for two seconds in turn, before stopping and moving to the next. This was designed to mimic the neon signs you often see at cinema theaters. I had to program this functionality instead of using traditional animation techniques, as changing the color via animation wouldn’t work for dynamic updates. If I were to use the BSDF node for animation and change the color on a surface level, the next time the code ran, the color would need to be manually adjusted again, which wouldn’t be ideal for a live update.
I initially designed the system so that Blender, acting as the client, continuously listens for new data updates from the server via sockets. The server scrapes fresh data every few minutes to keep the visualization as “live” as possible. After scraping, the server sends the latest data to Blender and then waits before scraping again.
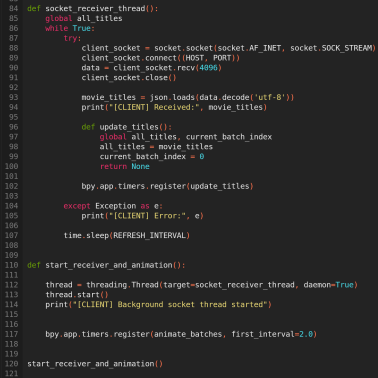
Then, I worked on the movement logic where one of the batches would slowly slide down after being visualised. There were a few glitches, but since the news was done before, I used some of the logic from there to get it working properly. Here, I was working with many text objects for all the titles and batches of five movies respectively.
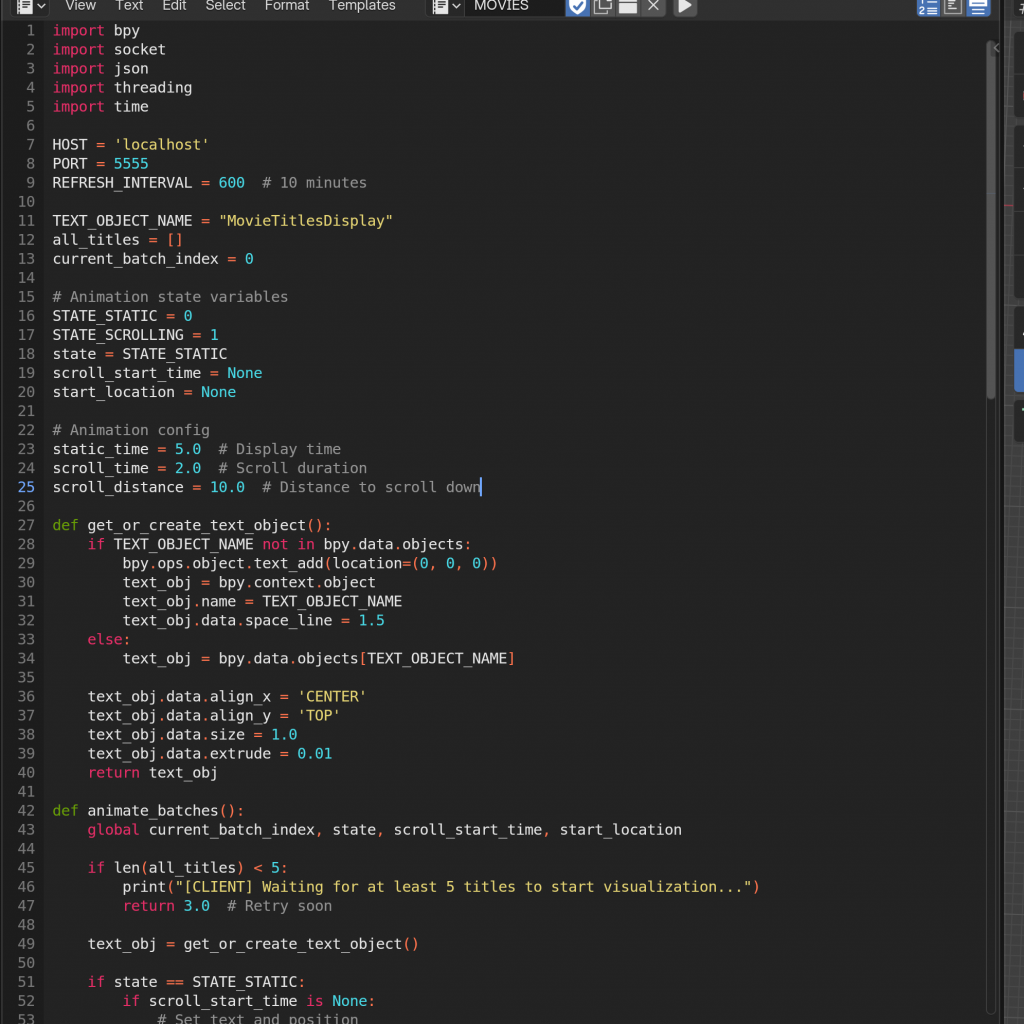
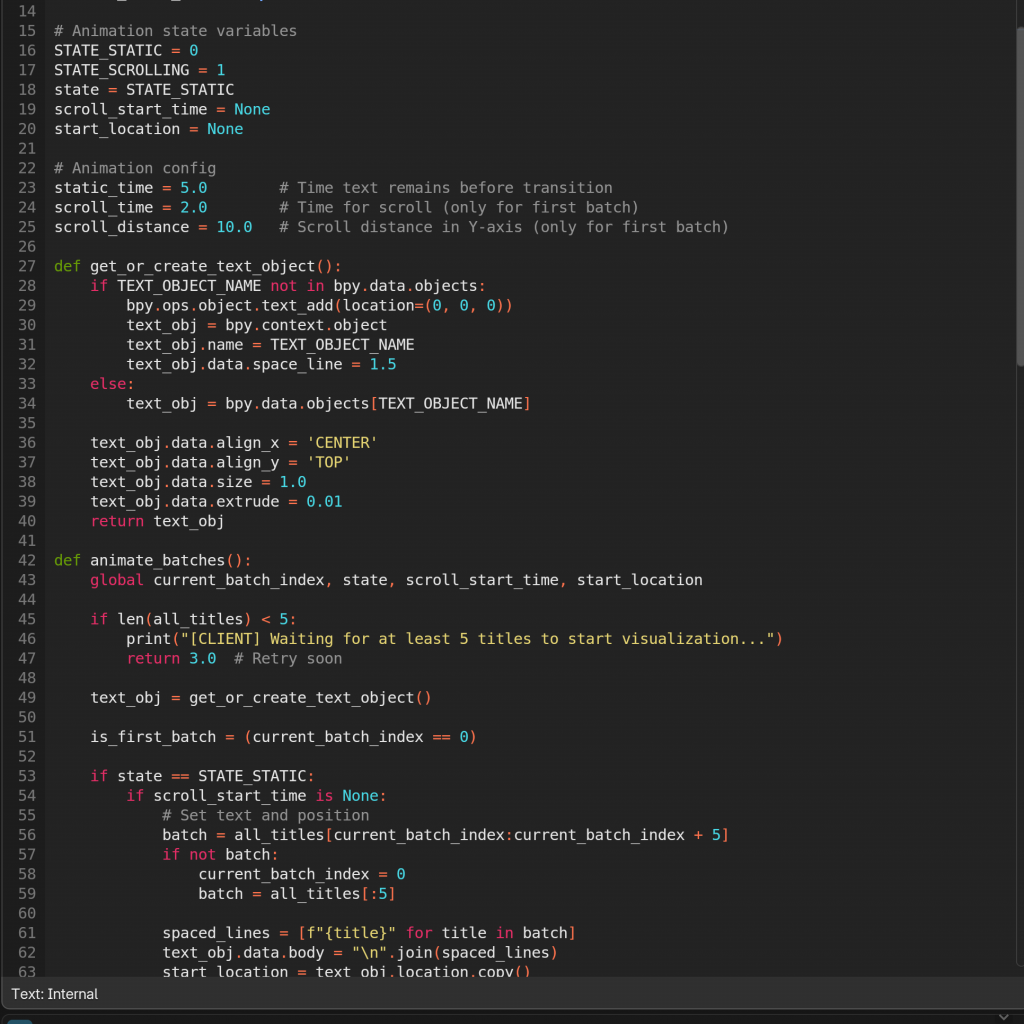
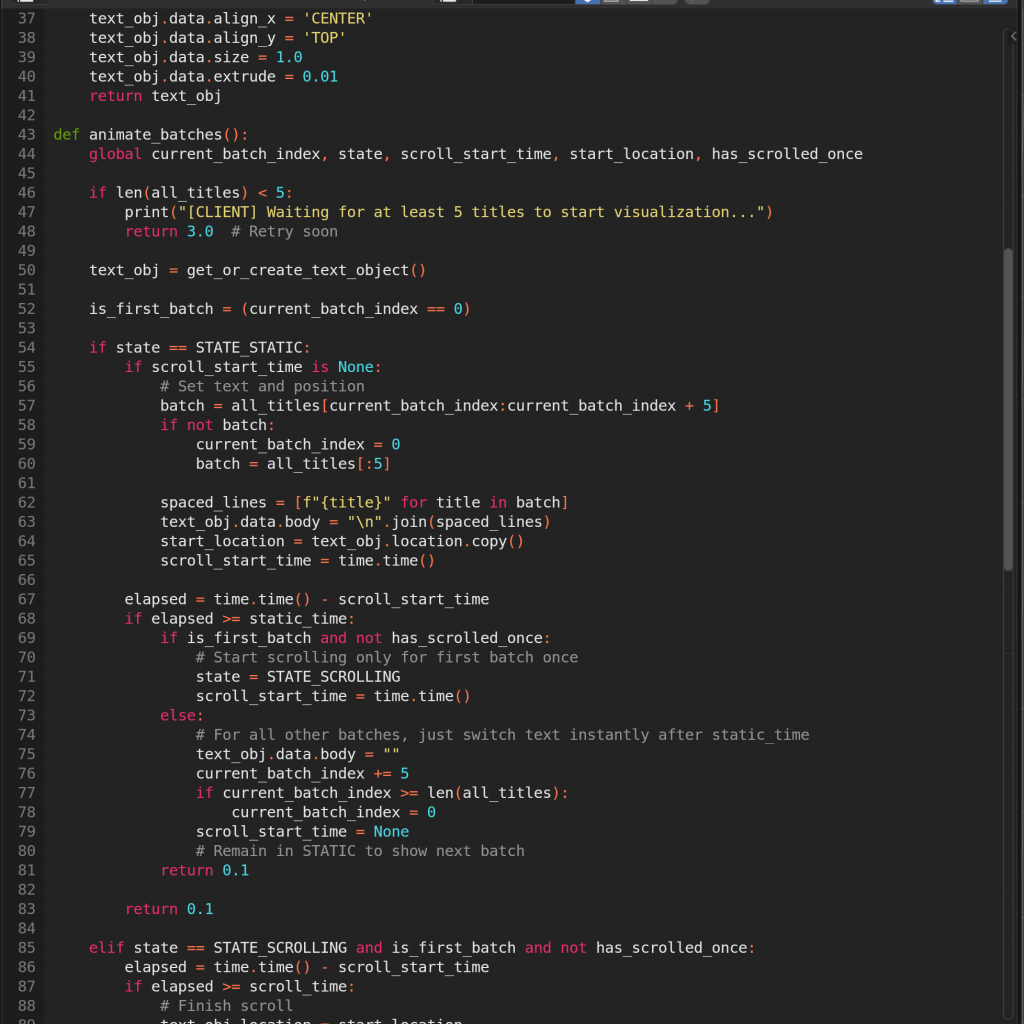
This setup was originally designed to support near real-time updates, with Blender dynamically refreshing its visuals based on the latest incoming data. I went through several iterations to figure out the best communication model — deciding which side should listen, when, and how frequently the data should be scraped and sent. Initially, I had Blender (the client) set to listen for updates only every ten minutes. Later, I revised the logic so that Blender would always stay ready to receive, while the server (after scraping new data) would wake up every ten minutes and send the latest information. Blender would then update its visuals accordingly.
I also went through a stage where I realised Blender needs a minimum amount of data to start visualising. So, when combining the scripts, I made it wait until enough data had arrived before starting the visuals. The idea was that once the minimum data was in, it could begin playing, and then continue updating with new data as it came in, adjusting each loop accordingly, instead of perhaps starting the video when no data had come in yet and messing it up.
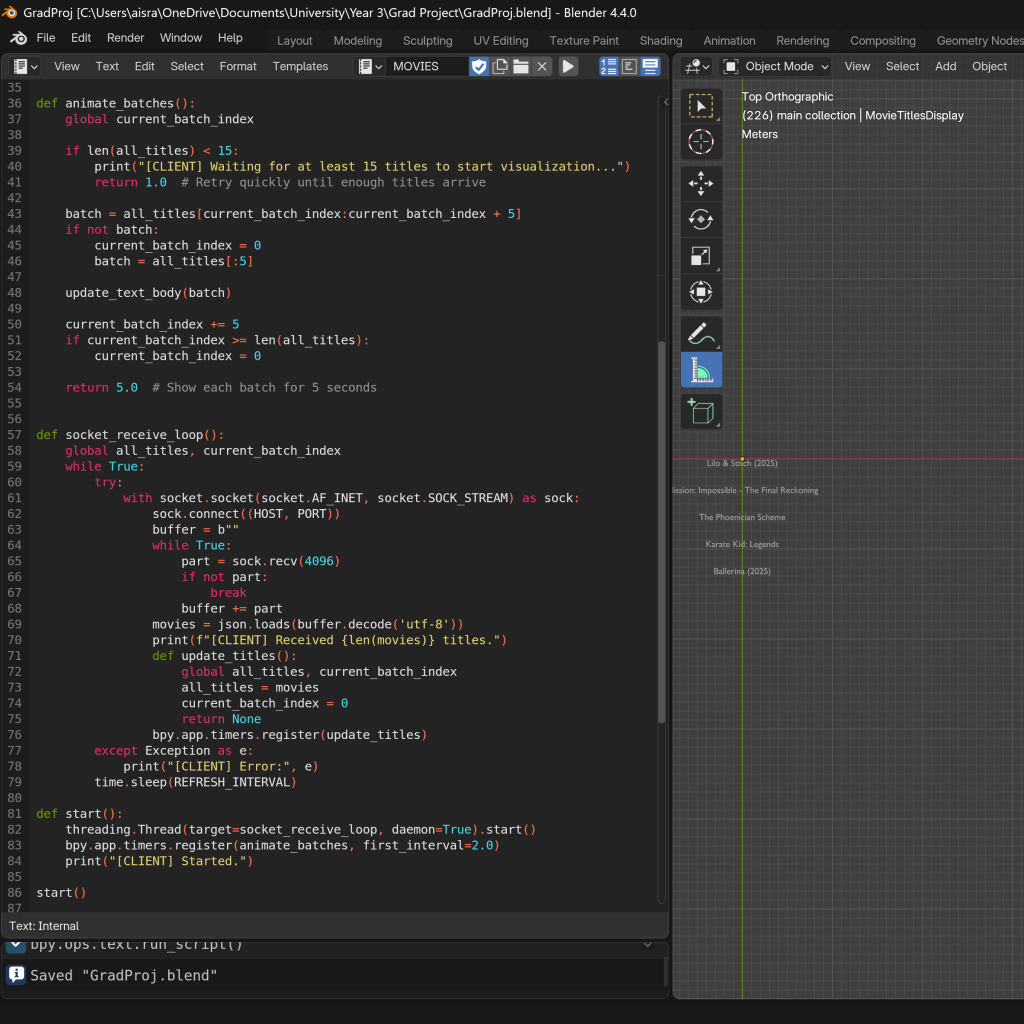
However, after going through a lot of trouble doing the news scraping and the visualization pipeline, I reconsidered the approach of constant scraping and pushing, and minimum requirements, which made Blender falter as well as mess up timing and sync with the video. I decided to remove the constant scraping loop, and Blender listening always and updating when new data comes in for a few reasons:
Simpler Flow: A more controlled, request-based approach or timed batch updates may be easier to maintain and scale.
Resource Efficiency: Continuous scraping was resource-intensive and caused rate-limiting or IP blocking from my source website, so I sometimes couldn’t even meet the minimum data that needs to be scraped and sent for Blender to start.
Stability: Constant open socket connections and repeated data pushes increased complexity and errors and glitches.
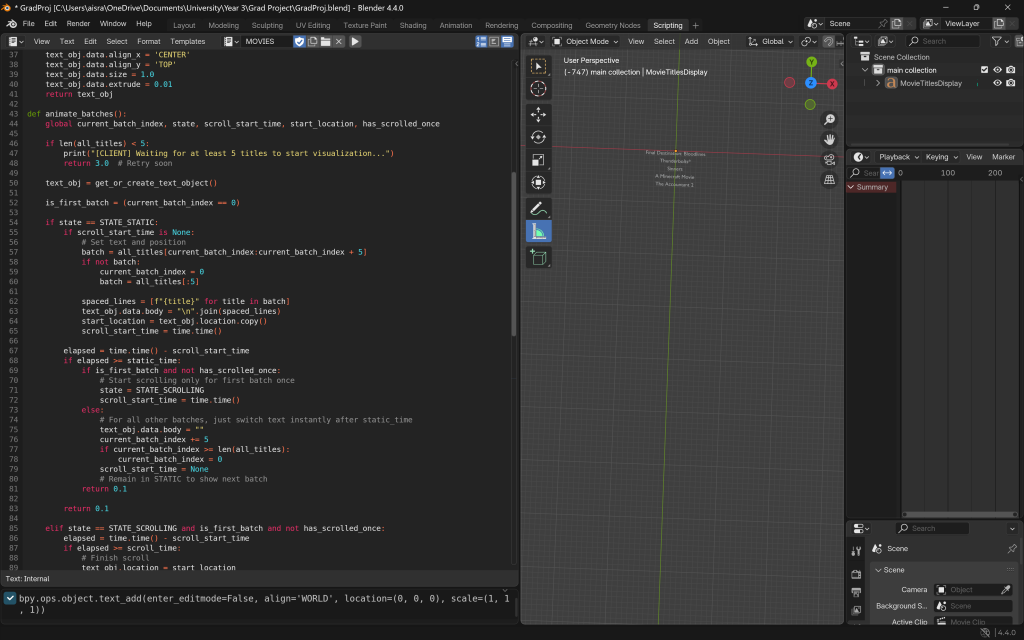
I also decided to, instead of having each of each movie title as a separate object, append to and and change a single object instead. The rationale was that, it would be easier to move and animate, if there were not so many objects collecting, especially when paired with the other datapoints. I was originally adding individual logic for each batch and each individual title that would appear, but this new approach had far less glitch and went smoothly, so even if I had less flexibility with the movement, it was better to handle.
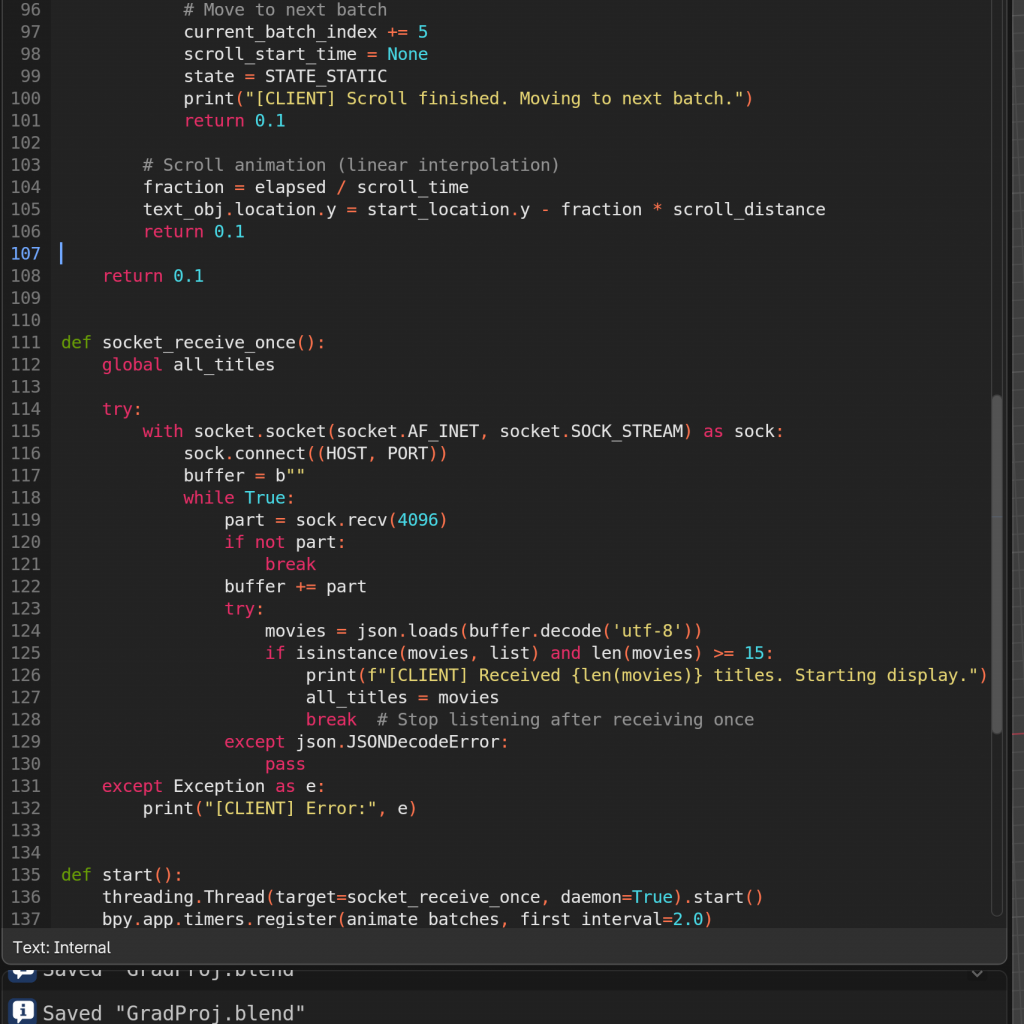
Once this was done, and after a gap in time during which I explored scraping news data and being confronted with the reality of what I could complete before submission, I returned to this with a fresh perspective. I realised that the overall process needed simplification. So, I made several adjustments to streamline everything—from how data was scraped to how it was visualised—removing unnecessary complexity wherever possible.
Thus, I finalised and simplified the logic for both sides, bypassing the loops, the sleeps, the listens, the prints, anything that was not strictly necessary. Based on the evaluation for what was possible in time for the submission mentioned prior, I decided the procedure would be->
a) server scrapes upon run, collects the data, and waits for client (Blender) to connect)
b) upon client connection, sends the data and shuts off the connection
The functionalities such as looping and true real time, I decided to improve and implement the logic, and get closer to true real-time, for the exhibition as I would have more time.