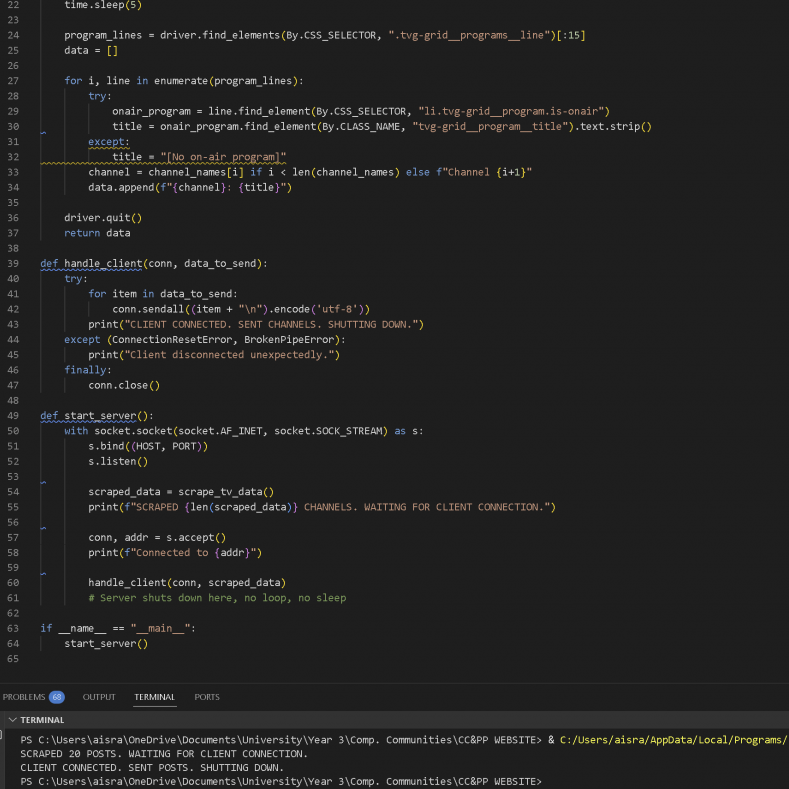
I first started by attempting to scrape https://www.radiotimes.com/tv/tv-listings/, as it had a clear structure and programming structure. Initial scraping tests went well and it was easy to obtain the information I wanted: The name of the top 5 channels and the programme that was currently running.
Then, I had to find the corresponding programme titles after the channel names. I had to face a long period of trial and error with the structuring and deducing which path would be best. I was unable to access the programmes themselves but scraping the channels was pretty straightforward.
I tried then to not deduce the programme titles by class names and ID selectors, but by the XPath. This also threw errors regardless of the small debugging I would keep attempting. I thought it may be an issue with the XPath nd did some tests by trying to obtain channel names like this, but this worked. I slowly started realising that this was not the issue of how it was accessed but perhaps because it may be because the programmes are loaded dynamically after the page render – so, even with time.sleep(5), Selenium might reach the elements before the JavaScript finishes inserting programme data.
I also thought it might be because sometimes elements aren’t attached to the DOM immediately or are hidden until interaction (like scrolling or hovering). But in this case, they should be in the DOM after JS loads them. So I started over, and scraped one by one starting from the channel names.
I noticed that the XPaths had a creating pattern in terms of what I wanted to access so I tried using logic to access them mathematically, but as I had expected, this too did not work, as the problem did not lie with this. However, I did not know what the problem did lie in.
I tried using CSS selectors too to extract the information, since if the class names were not static or are combined with other dynamic names, using a CSS selector might have helped, but this also led nowhere. I also tried the JS path, and a few other ways to access the data in case the fault lay with my method of accessing the data.
I checked if the element might be inside an <iframe>, since that would require me to switch to the iframe using driver.switch_to.frame() before accessing anything inside it. I also realized the page could be using AJAX to load content dynamically, so I added longer waits to give everything time to render. Even then, I wasn’t sure if the element was just in the DOM or actually visible and interactable. To double-check, I ran the script without headless mode and used the browser’s dev tools to inspect the page manually. That helped me confirm whether my CSS selector was correct and whether the element was actually loading as expected.
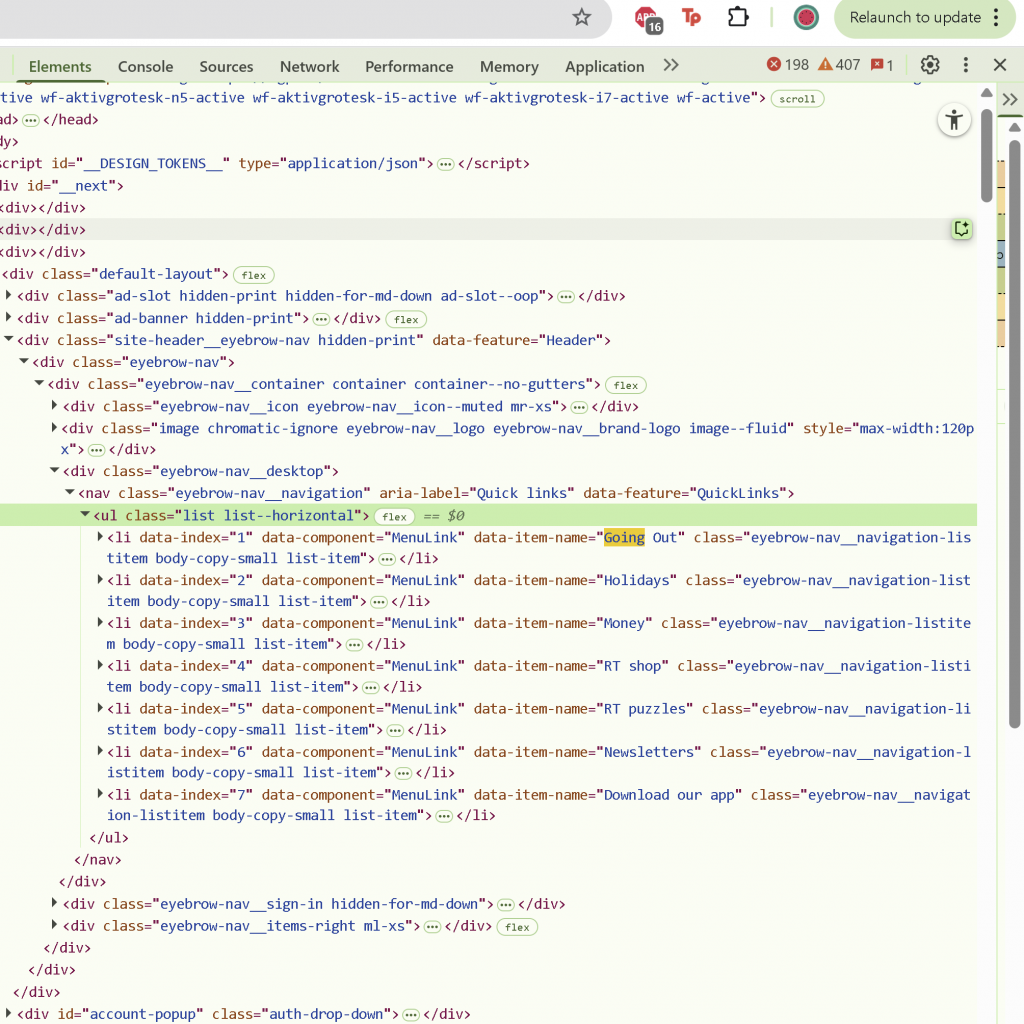
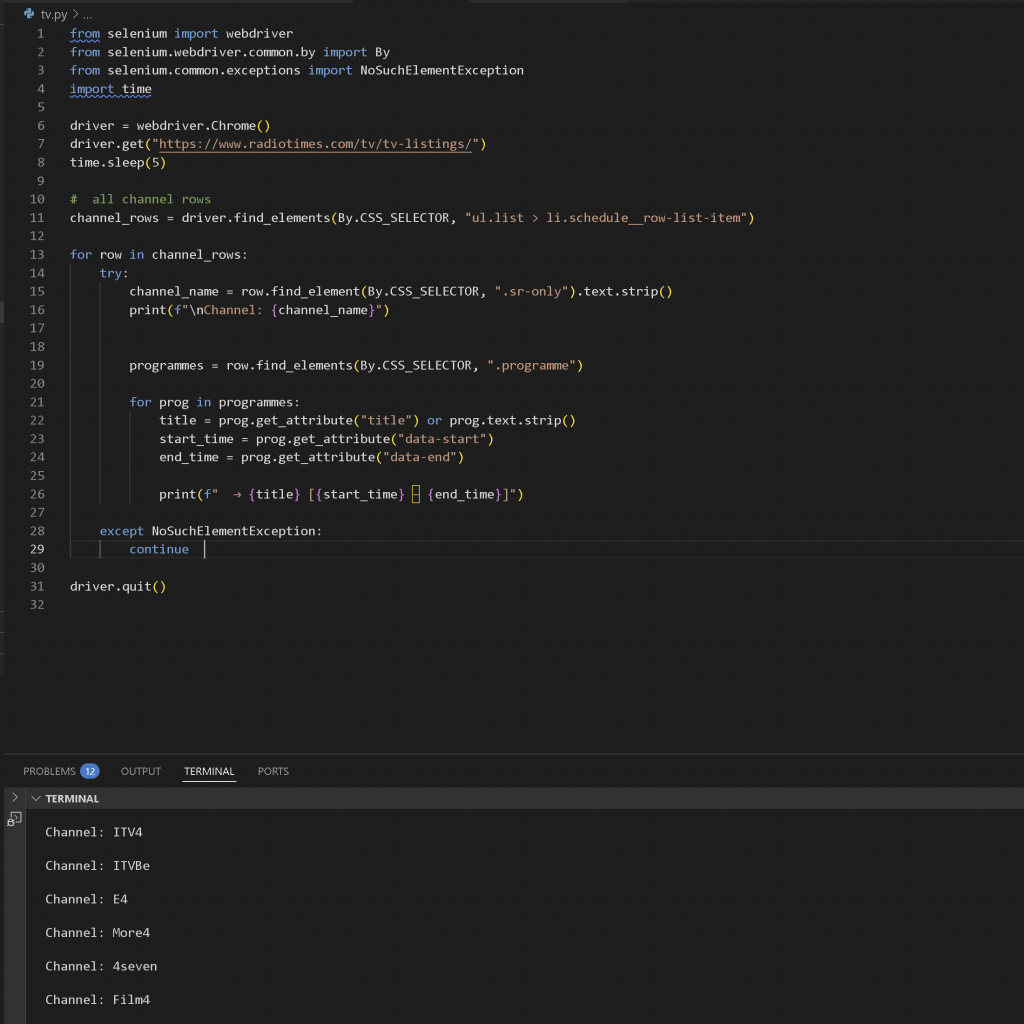
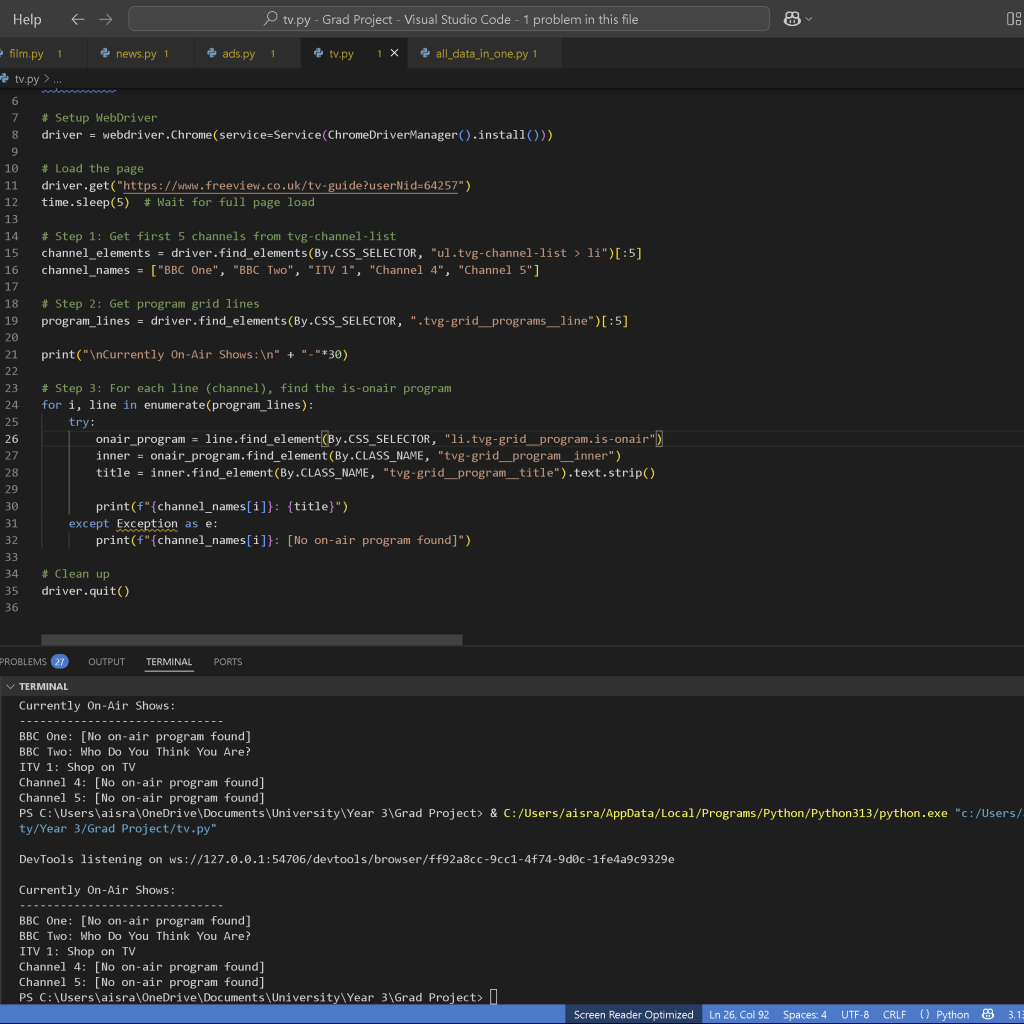
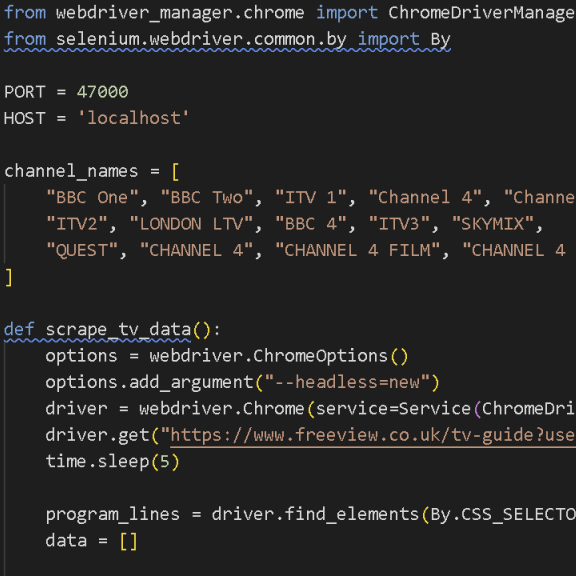
After a few days struggling with this, I just decided to switch the scraping source, and found https://www.freeview.co.uk/tv-guide?userNid=64257. When I looked through the structure, it was far more simply laid out than the previous, and had clear indication of what was airing through (li.tvg-grid__program.is-onair)
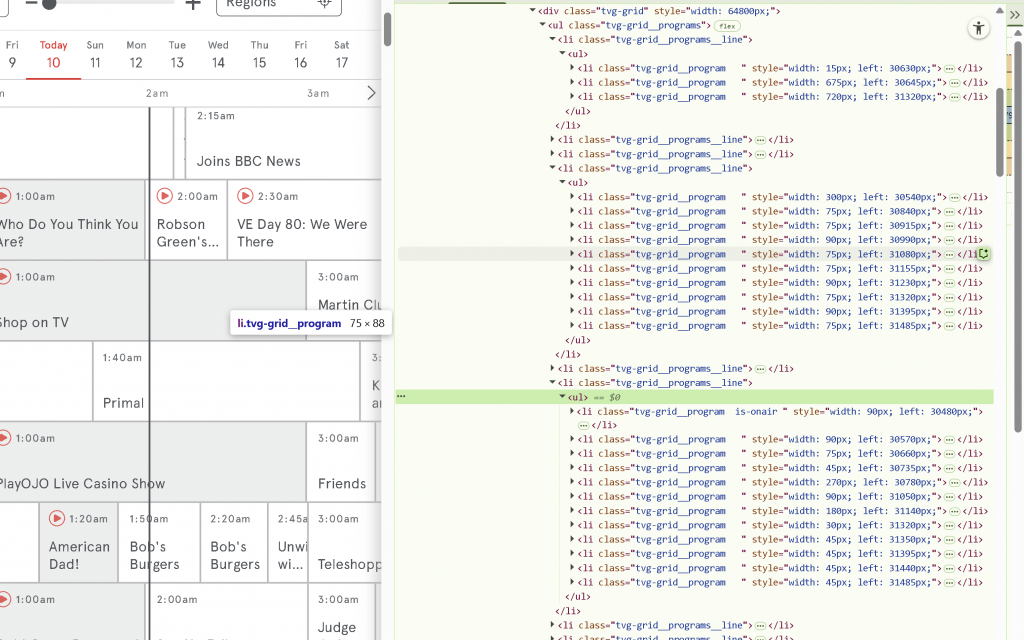
It was pretty easy to get what I needed due to the structure being so clear.
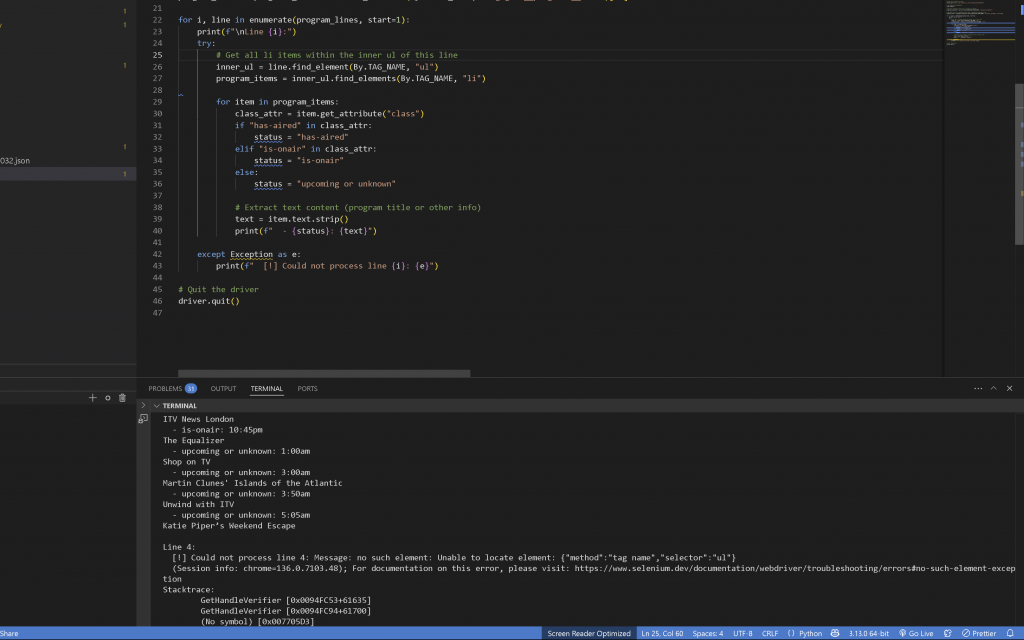
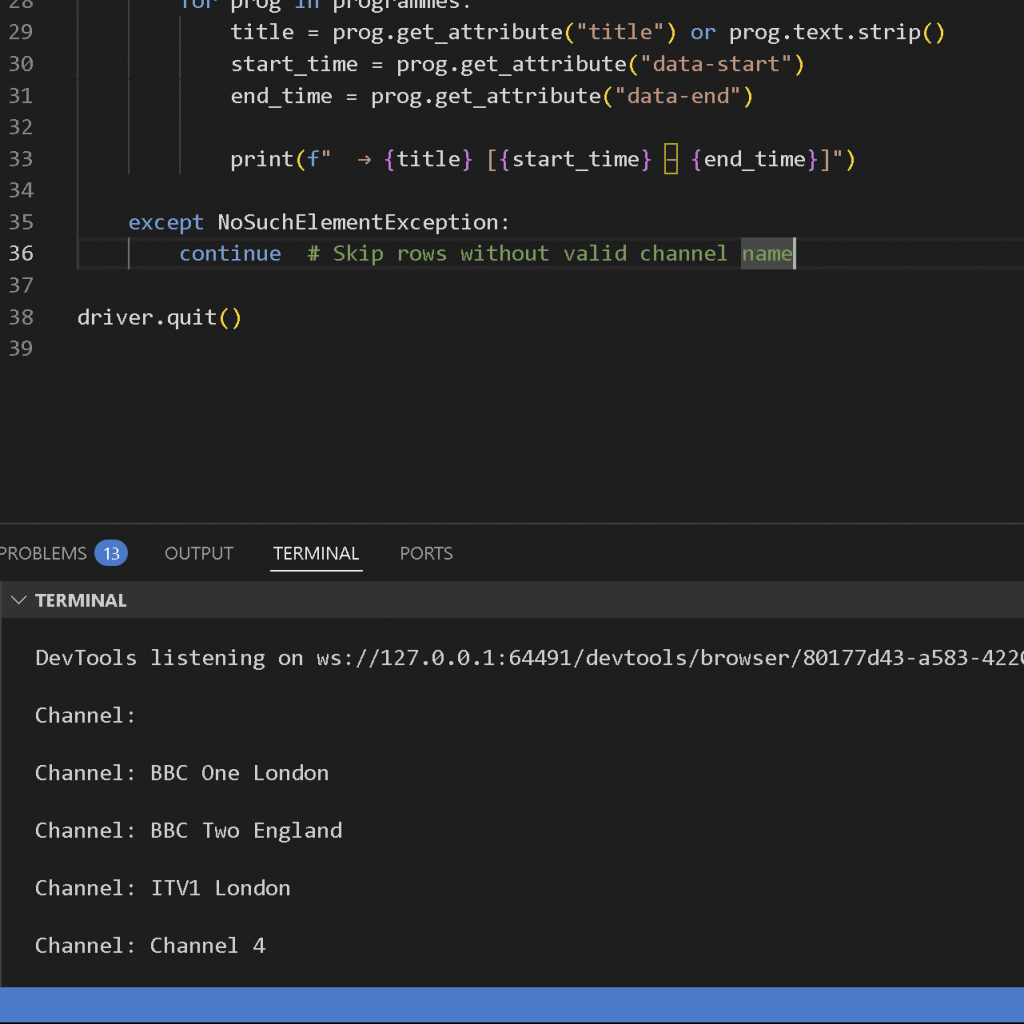
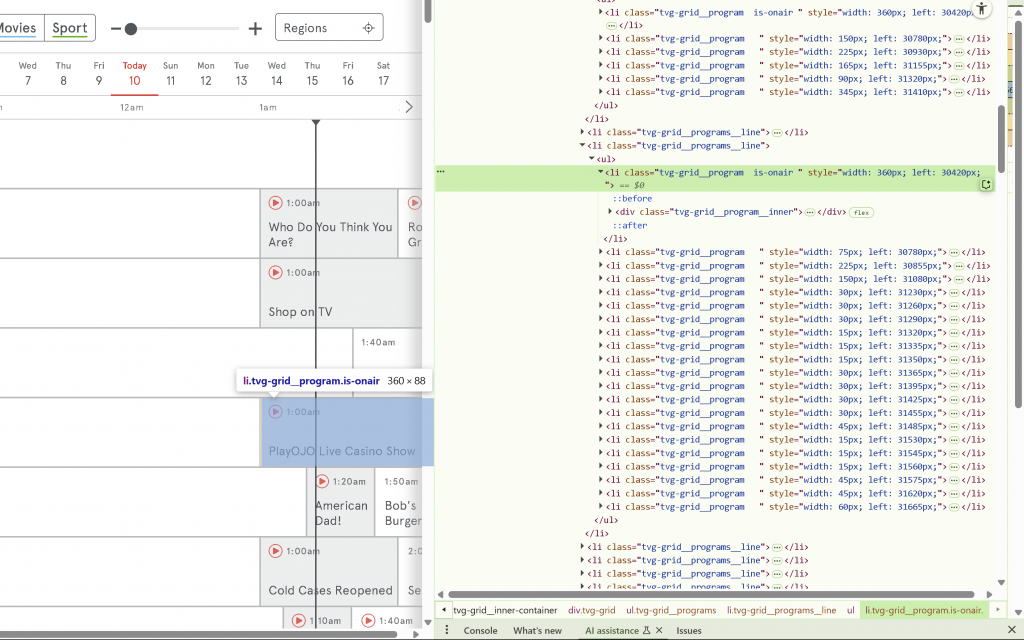
I did end up with a point of confusion: while Channel 5 has something on air in the structure, it would not show up in the scraped results, regardless of different approaches tried. I decided to ignore it for the time being and quickly visualise it as less time was left.
Working with the different axis in a 3D plane was still as difficult but I learned quite a bit along the way about the 3D coordinate system in Blender.
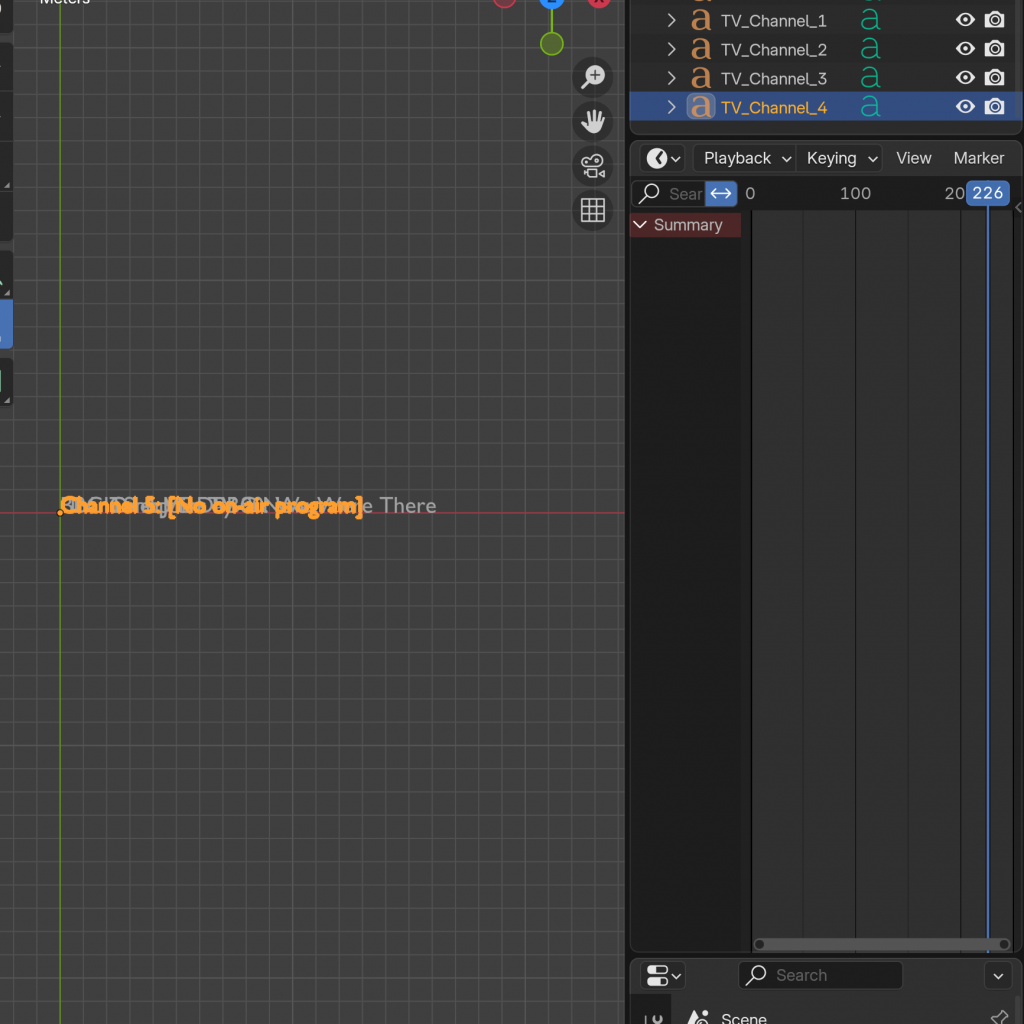
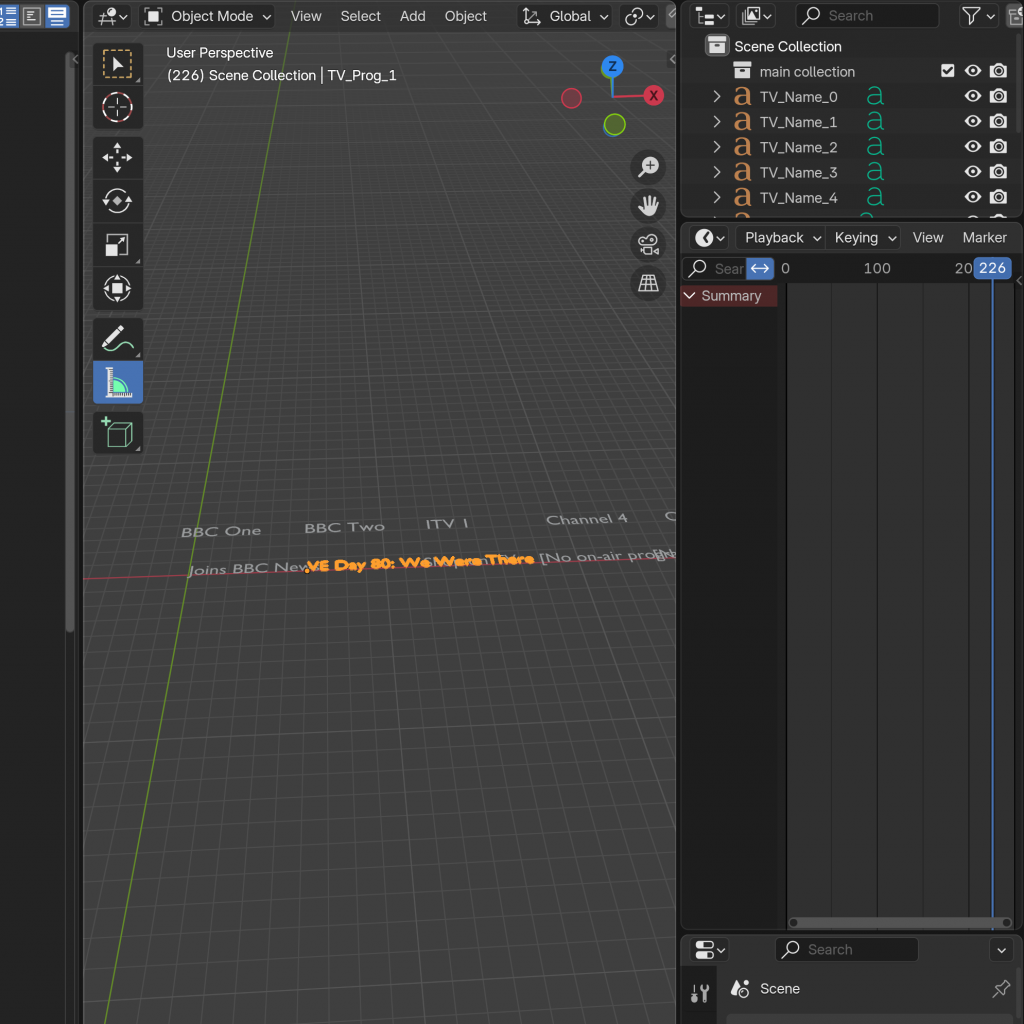
Having familiarity already, having done this a few times, it visualised pretty quickly, and after spending some time fiddling around with spacing, I obtained a satisfactory result. However, this created five text objects which would be individually updated, and since they were all to move together (in my idea for the animation) and there was no individual movement of a channel, I wanted to make them all into one text object for my ease and for decluttering purposes.
This approach made it difficult to control the spacing and line indentation exactly how I wanted. Despite several attempts to restore the original formatting, I couldn’t achieve it within a single text object in Blender. So, for the sake of convenience and getting things working, I decided to continue using just one text object for now. If this posed a significant issue when layering it with the animation later, I planned to revise it. And for the exhibition version, I committed to definitely revisiting and refining the text formatting properly.
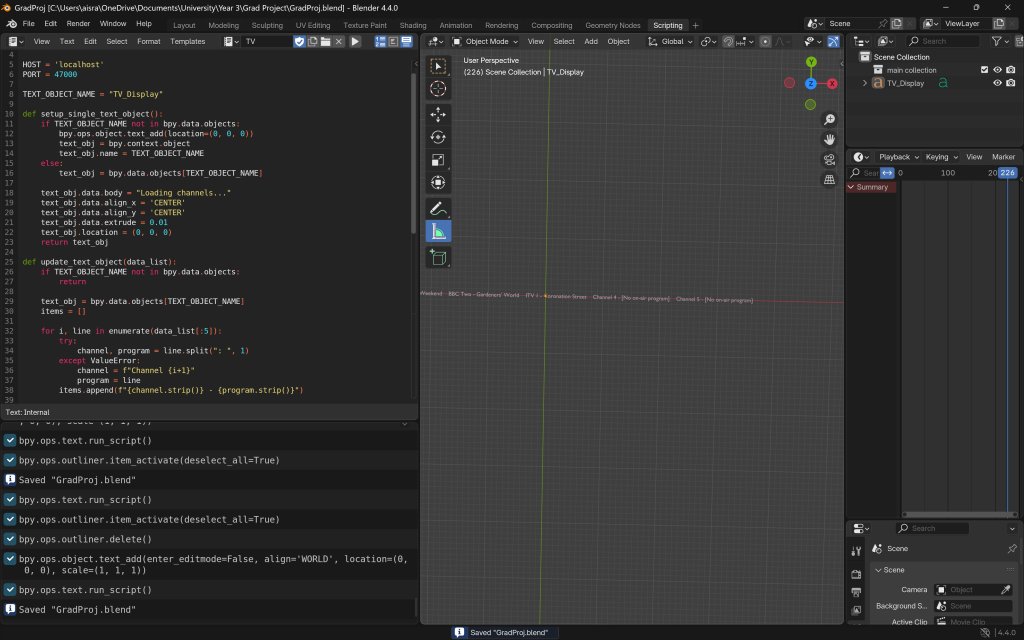
It was then time to implement the animation logic. I designed it so that, after remaining static for a few seconds, the text would slide down along the Y-axis. When layered with the animation video, this would give the effect of the text sliding off a television screen. However, implementing this proved surprisingly time-consuming. Since I was working with only five channels and wanted to give the impression that the data following the character was constantly being replaced—reflecting the ever-updating nature of media—I attempted to create a duplicate of the text. The idea was that while the original scrolled down, the duplicate would stay in place, creating a seamless transition. Unfortunately, this duplicate creation logic turned out to be buggy and glitchy, causing more issues than expected.
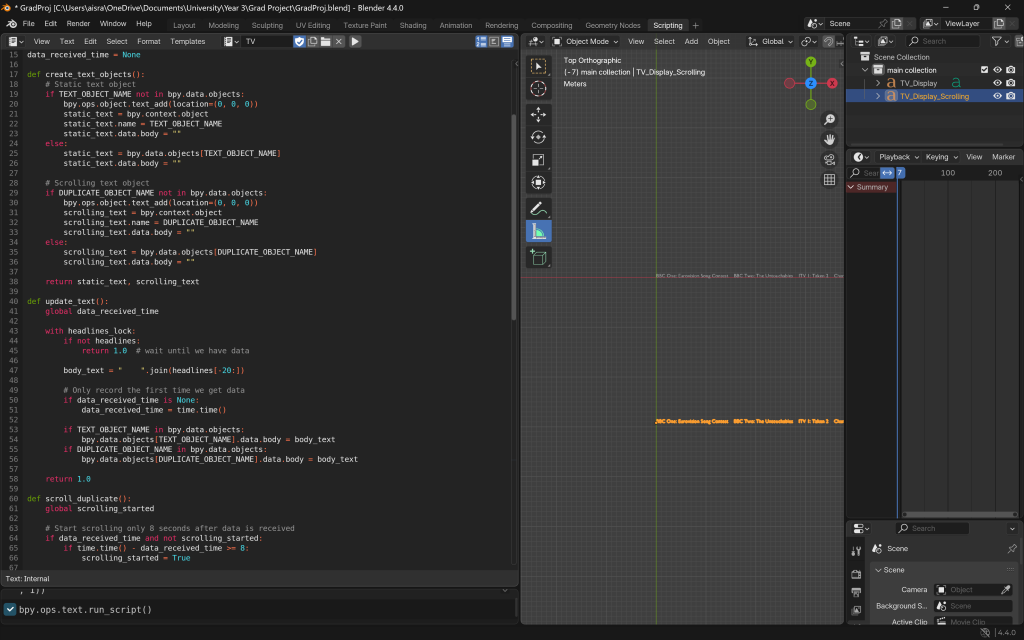
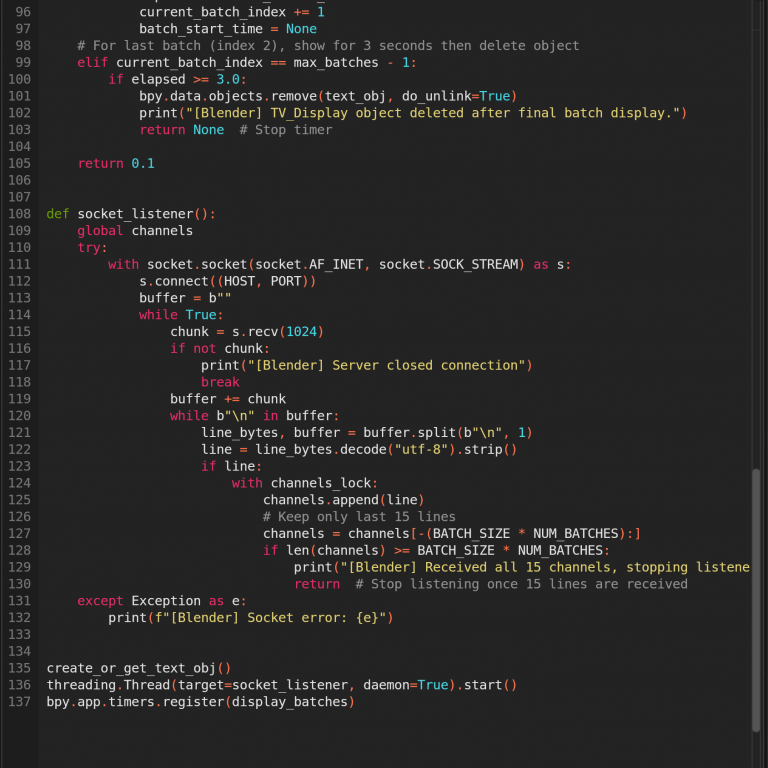
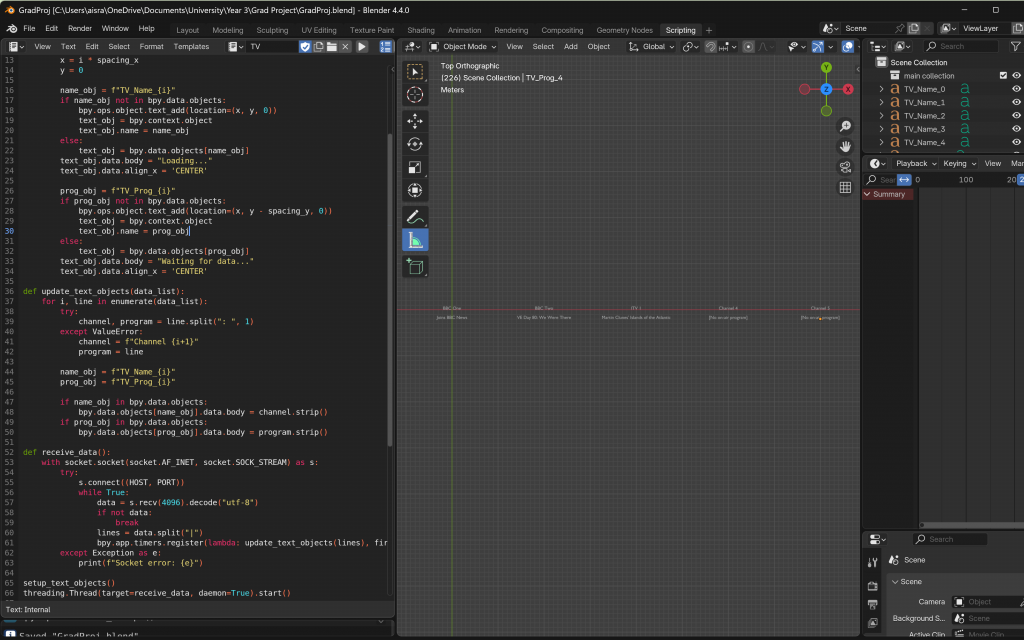
So, I returned to the server-side script—which was originally scraping the top five channels—and modified it to scrape the top 15 instead. On the Blender side, I visualized this data in batches of five, displayed over three sequential rounds. This approach worked much better: it allowed each batch (first or second) to slide out and be smoothly replaced by the next, eliminating the need for glitchy duplication logic. That said, I once again ran into issues with spacing and alignment, accidentally messing up the layout. But after some careful adjustments, I managed to get everything working the way I intended.
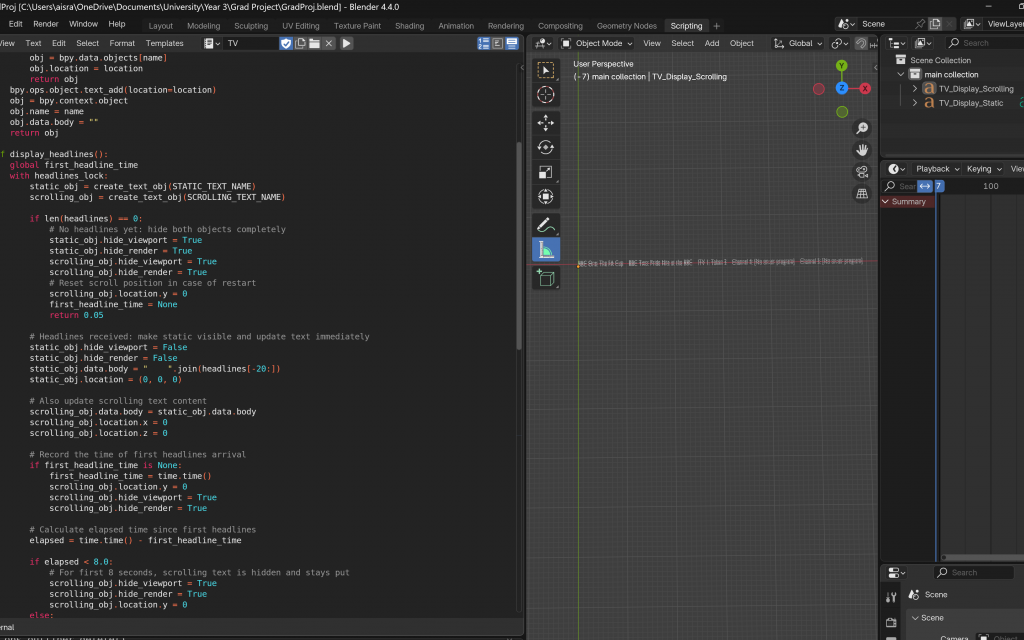
Once this was done, and after a gap in time during which I explored scraping news data and being confronted with the reality of what I could complete before submission, I returned to this with a fresh perspective. I realised that the overall process needed simplification. So, I made several adjustments to streamline everything—from how data was scraped to how it was visualised—removing unnecessary complexity wherever possible.
Finally, I made adjustments to simplify the entire process. I removed the looping logic and stopped Blender from always listening on the socket. Instead, the server now scrapes the necessary data just once, sends it to Blender upon connection, and then shuts down—no more sleeping and re-sending. On Blender’s side, it receives the data once, updates accordingly, and proceeds with the animation without waiting for further updates. These would be added, i.e. live data streams and seamless looping, for the exhbition.